AWS SAA
AWSの仕組み
- インフラやアプリ開発に必要な機能がオンデマンドのパーツサービスとして提供されている
- サーバーを立ち上げるのに数分で無料で今すぐに利用できることが特徴
- インフラ/システム機能をブロックパーツのようにオンライン上に組み合わせて自分の好きな構成を実現する仕組み
- AWSのサービスにはアンマネージド型とマネージド型が存在する
- アンマネージド型
- スケーリング/耐障害性/可用性を利用者側で設定し管理する必要がある
- メリット
- 設定が柔軟に可能
- デメリット
- 管理が面倒
- マネージド型
- スケーリング/耐障害性/可用性がサービスに組み込まれておりAWS側で管理されている
- メリット
- 管理が楽
- デメリット
- 設定が限定的
- アンマネージド型
AWSのグローバルインフラ構成
- リージョン
- AZ(アベイラビリティゾーン)
- エッジロケーション
- エッジロケーションはキャッシュデータなどを利用する際の更に小さなエンドポイントとなる拠点
- エンドポイントとはITの分野では、通信ネットワークの末端に接続された機器や端末、あるいは利用者が直に触れて操作する機器などを指すことが多い。
- cloudfrontなどもエッジロケーションの1つ
- エッジロケーションはキャッシュデータなどを利用する際の更に小さなエンドポイントとなる拠点

仮想化を理解する
クラウドと仮想化
- クラウドは仮想化技術によって成り立っているサービス
- 仮想化とインフラの構成を隠して仮想化された単位に分けたり統合したり利用させる技術
- 物理的なインフラに仮想化ソフトウェアを設定して、実質的な機能をユーザーに切り分けて提供する
仮想化の対象
- サーバーの仮想化
- 1台の物理サーバ上に複数のOSを起動させる技
- ハイパーバイザー型・VMmare型・コンテナ型
- ストレージの仮想化
- 複数のストレージを仮想的に統合して1つの大きなストレージプールを構成する
- ブロックレベル仮想化/ファイルレベル仮想化
- ネットワークの仮想化
- 新たな仮想ネットワークの構築や制御を、ソフトウェアにより動的に実施する技術
- SDN・VLAN
- デスクトップの仮想化
- サーバ上においてPC環境のデスクトップ画面を遠隔地にある接続端末に転送する技術
- 仮想PC方式・ブレードPC方式
仮想化のメリット
仮想化を利用することでインフラ利用の効率性や柔軟性が圧倒的に向上する
- サーバースペースの削除・データセンター費用の削減
- 効率的なサーバー利用によるコスト削減
- 調達の迅速化
- 構成変更やメンテナンス対応の柔軟性
- セキュリティの向上
クラウドとは
- 必要に応じて他社所有のハードウェア・ソフトウェア等をネットワークを介して利用するシステム利用形態
- インフラを仮想化することでソフトウェア化されたサービスとして提供されていることでソフトウェア化されたサービスとして提供されているされているのがクラウド型のサービス
クラウド構成要素
クラウドで提供されるシステム構成要素はインフラ、ミドルウェア、アプリケーションの3層
- アプリケーション
- プログラミング開発したアプリケーション
- 業務機能が実装されたパッケージソフトウェア
- ミドルウェア
- ミドルウェアとは共通利用される機能をまとめたソフトウェア
- データベース、Web・アプリケーションサーバ
- インフラ
- 物理的な機器
- ネットワーク回線
クラウドの5つの基本特性
- オンデマンド・セルフサービス
- 利用者は人を介さず、必要に応じてサーバー、ネットワーク、ストレージを設置・拡張・設定が可能
- 幅広いネットワークアクセス
- リソース共有
- ハードウェアの使用容量などのリソースは複数利用者により共有し、利用者の需要に応じて動的に割り当てる
- 迅速な拡張性
- ハードウェア等の資源は必要に応じて自動または手動で増やしたり、減らしたりできる
- サービスは計測可能
- 稼働状況が常に計測されており、利用状況をコントロール・最適化できる
- 計測結果に応じて重量課金が可能
IAM
IAMの概要
IAMとはIdentity and Access Managementは安全にAWS操作を実装するための認証・認可の仕組み
- AWS利用者認証の実施
- アクセスポリシーの設定
- 個人またはグループに設定

https://recipe.kc-cloud.jp/archives/11054
主要トピック
ユーザー、グループ、ポリシー、ロールがIAMの主要な要素
IAMポリシー

IAMユーザー
AWS上の利用者はIAMユーザーという権限を付与されたエンティティとして認定される
- ルートアカウント
- 管理者権限
- 管理者権限の許可が付与されたIAMユーザーのこと
- IAMの操作権限まであり
- ルートアカウントしかできない権限は付与されない
- パワーユーザー
- パワーユーザーはIAM以外の全てのAWSサービスにフルアクセス権限を有するIAMユーザー
- IAMの操作権限なし
IAMグループ
- グループとして権限をまとめて設定される単位のこと
- グループには通常複数のIAMユーザーが設定される
IAMロール
- AWSリソースに対してアクセス権限をロールとして付与できる
- EC2から特定のS3にアクセスできないよう制限をかけたりすることが可能
IAMの認証方式
IAMによるユーザー認証方式は利用するツールに応じて異なる
- アクセスキーID/シークレットアクセスキー
- X.509 Certificate
- AWSマネージメントコンソールへのログインパスワード
- AWSアカウントごとにパスワードを設定してログイン認証をする
- デフォルトは未設定(ログインできない)
- MFA(他要素認証)
- 物理デバイスなどを利用したピンコードによる認証方式
- ルートアカウントなどはMFAを付与してセキュリティを強化することで推奨される
IAM設計
AWSを利用するユーザーの役割やアクセス権限を自社の組織構造と合わせて設計することが重要
- 少数利用がずっと継続する場合は少数利用も含めて最初からIAMグループで設定する方が良い
グループ設計
組織別または個人単位にAWS利用者とその役割別の利用範囲を整理して、グループ設計を実施する
IAMロールへのポリシー適用
システム設計からAWSサービス間の連携有無を抽出する
- システム設計
- システム設計からAWSサービス間の連携箇所を特定
- 必要な権限設定の設定
- リソースに対して必要な権限設定の割り出しを実施
IAMロールの信頼ポリシー
IAMロールは監査人などに一時的な権限を委譲する際にも利用される
- IAMロールの権限委譲操作に特化したポリシー
- 当該の信頼ポリシーを関連づけたIAMロールが保有する情報を、信頼ポリシーの操作主体であるPrincipalに委譲(許可)することができる
VPC
IPアドレスの基礎
- ネットワーク機器やWEBサイトなどの場所を特定するためにIPアドレスを利用する
- IPアドレスは重複されない許されない一意の32ビットデータ
- ICANNという非営利団体が管理する
- IPアドレスは重複が許されない
- IPアドレスは32ビットの数値データ
- ネットワークインターフェースカード(NIC)に割り当てられ、ホストにアタッチされる
- 最も普及しているグローバルIPアドレスであるIPv4は枯渇しつつあるため、IPアドレスが足りない
- IPv6を利用することで無制限に違いIPアドレスを利用できる
グローバルとプライベートのIPアドレス
プライベートIPアドレス
10.0.0.0 ~ 10.255.255.255 172.16.0.0 ~ 172.32.255.255 192.168.0.0 ~ 192.168.255.255
サブネットとサブネットマスク
ネットワークの範囲
- ネットワークの範囲を定義することが必要
- ネットワークの範囲=IPアドレスの利用可能な範囲
- プライベートネットワークをサブネットに分けることができる
- 表記方法
10.0.1.0/16
CIDR(Classlesss Inter-Domain Routing)
196.51.×××.×××/16 左から16桁目までが同じネットワーク範囲と指定
ネットワーク部とホスト部
サブネットによるグループ化
- ローカルなネットワークに沢山の機器がつながっている特定の端末を発見しづらい
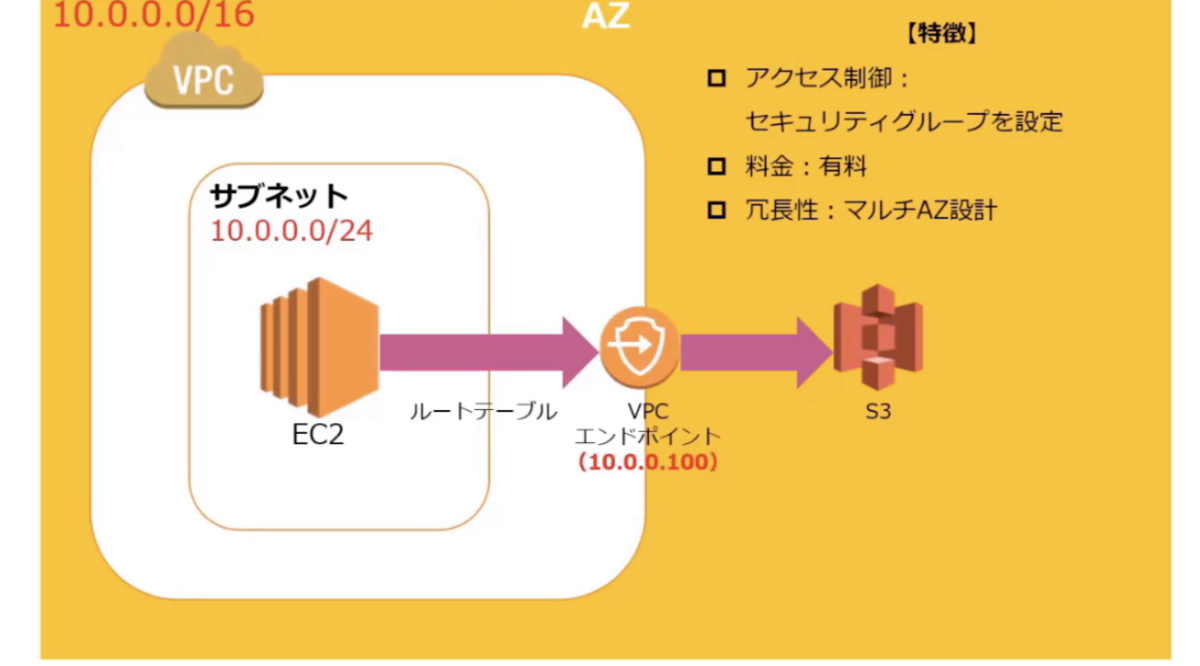
VPCの概要
VPC(Virtual Private Cloud)はAWSクラウドのネットワークからユーザー専用の領域を切り出してくれる仮想ネットワークサービス
- 任意のIPアドレスを範囲を選択して仮想ネットワークを構築
- サブネットの作成、ルートテーブルやネットワークゲートウェイの設定など仮想ネットワーキング環境を完全に制御可能
- 必要に応じてクラウド内外のネットワーク同士を接続することも可能
- 複数の接続オプションが利用可能
- 単一のVPCを構築すると単一AZの範囲に認定される
- 同一リージョン内ではVPCは複数のAZにリソースを含めることもできる
- VPCとサブネットの組み合わせでネットワーク空間を構築する
- VPCはサブネットとのセットが必須
VPCの設定
VPCウィザードを利用しない場合はVPCを作成、サブネットを作成と1つずつ作成する
サブネット
- サブネットはCIDR範囲で分割したネットワーク
- VPCとサブネットにはCIDR(IPアドレス範囲)が付与され、ネットワークレンジが決まる
- インターネットゲートウェイへのルーティング有無でサブネットのタイプが分かれる
VPC外部接続
インターネット経路を設定

AWSのルートテーブルは、 サブネット内にあるインスタンス等がどこに通信にいくかのルールを定めたものです。つまり、ルートテーブルはパケットの宛先(IPアドレス)を見て、どこに通信を流すかが書かれている表です。この表をみてパケットを運ぶので、表にない宛先のものはパケットを送らないので、通信できません。サブネット毎にどこに通信ができるかを定めたものだというところがポイントです。

ルートテーブルの役割
- パブリックサブネットからインターネットに接続するにはインターネットゲートウェイが必要
- インターネットゲートウェイはルーターの1つ
- サブネットのルートテーブルにインタネットゲートウェイへのルートを設定することでパブリックサブネットになる

プライベートサブネットを作成する
グローバルとプライベートのIPアドレス
- IPアドレスはグローバルIPアドレスとプライベートIPアドレスで使い方が分かれる
- DHCOサーバーがローカル端末に対してプライベートIPアドレスを付与して、接続できるようにする
- IPアドレスとして利用範囲を決めるのがサブネットマスクという機能
グローバルIPアドレスとプライベートIPアドレスを対応付けるのがNATというの機器またはソフトウェア

NATが1対1で変換するのに対して、IPマスカレードは複数のプライベートIPアドレスをグローバルIPアドレスに変換する

- プライベートサブネット内のインスタンスに接続するには踏み台サーバーが必要
- 戻りトラフィックにはNATゲートウェイが必要

まとめ
- NATゲートウェイはグローバルIPアドレスとプライベートIPアドレスとを関連づけるアドレス変換を実施
- プライベートサブネットからの返信トラフィックはNATゲートウェイを介して変換されてインターネットゲートウェイに送ることができインターネットへの返信が可能になる
通信プロトコルとOSI参照モデル
- 通信のルール
- インターネットの通信の際にメールやWEBアクセスなど、目的によって通信方法が異なる
- HTTP(Hyper Text Transfer Protocol)はHTML(Hyper Text Markup Language)で書かれた文書などの情報をやり取りする時に使われるプロトコル\
- ポート番号
- 通信する出入り口となるのがポート番号で、メールボックスのような役割をになっている
- ポートとはオペレーティングシステムがデータ通信を行うためのエンドポイント
- インターネット上の通信プロトコルで同じコンピュータ内で動作する複数のソフトウェアのどれが通信するかを指定するための番号
セキュリティグループとネットワークACL
- セキュリティグループ
- ネットワークACL
NATゲートウェイ
- WEBさサーバーからプライベートサブネット内のEC2インスタンスにアクセスする
- プライベートサブネット内のインスタンスに接続する踏み台サーバーが必要。インターネットへのトラフィックにはNATゲートウェイが必要(ソフトウェア更新など)

VPCとの接続


EC2
公開鍵認証方式を学ぶ
- EC2インスタンスを作成した際にキーペアを作成して、PEMファイルをダウンロード
- 作成したEC2インスタンスが自分のモノであると証明するためにPEMという鍵を利用する
- キーペアであるため、EC2インスタンス側にも対になる鍵を持っている
- この認証方式を公開鍵認証方式という、基本的な暗号方式を利用している

- 秘密鍵
- 自分自身だけが所有しており、そのデータや領域が自分のものだと表明するための鍵
- 公開鍵
- 公開鍵は秘密鍵を利用する対象となる相手に共有することを目的とした公開された鍵
- 作成したEC2インスタンスに入る際は、このPEMを指定して認証することが必要
- EC2のPEMキーも1つで複数のEC2インスタンス用のカギとして利用することができる
SSHを学ぶ
- SSHプロトコルを利用してEC2インスタンスに安全な接続を実施する
- Linuxエンジニアにはお馴染みのリモートマシン操作ツール
- SSH(Secure Shell):クライアントとリモートマシン間の通信を暗号化するプロトコル
- SSHコマンド:SSH方式によってリモートマシン上でコマンドを実行するコマンド。主にLinuxサーバーの操作に利用
- SSHクライアント:SSHによるリモートマシン操作を支援するコマンドプロンプトタイプのソフトウェア
AMIイメージ
- AMIイメージからOSセッティング方式を選択すること
- 逆にEC2インスタンスの内容をAMIとしてバックアップ可能
- OSの設定情報
- サーバーの構成情報
- ルートボリュームに構成されたEBSやインスタンスストアのデータ
- AMIはリージョンにおいて一意のものであり、他のリージョンでそのまま利用できない
- EC2インスタンスはAMIを利用して起動・バックアップ・共有することができる
EBS
- EBSはEC2インスタンスと共に利用されるブロックストレージ
- インスタンス上のワークロード(仕事量、作業負荷)などに利用
- AWSは3つのストレージサービスを提供
- EC2が利用するのはインスタンスストアとEBSの2タイプのストレージ
- インスタンスストア
- ホストコンピュータに内蔵されたディスクでEC2と不可分のブロックレベルの物理ストレージ
- EC2の一時的なデータが保持され、EC2の停止・終了と共にデータがクリアされる
- 無料
- Elastic Block Store(EBS)
- ネットワークで接続されたブロックレベルのストレージでEC2とは独立管理
- EC2を終了してもEBSデータは保持可能
- SnapshotをS3に保持可能
- 別途EBS料金が必要
- インスタンスストア
- EBSの特徴
- スタップショット
- EBSはスナップショットを利用して取得する
- 特徴
- スナップショットでバックアップ
- スナップショットからEBSを復元する際は別AZにも可能
- スナップショットはS3に保存される
- スナップショットの2世代以降は増分を保存する増分バックアップとなる
- スナップショットとAMI

S3
AWSは3つの形式のストレージサービスを提供
- ブロックストレージ
- オブジェクトストレージ
- 安価かつ耐久性を持つオンラインストレージ
- オブジェクト形式でデータを保存
- 例:S3、Glacier
- ファイルストレージ
- 複数のEC2インスタンスから同時にアタッチ可能な共有ストレージサービス
- ファイル形式でデータを保存
- 例:EFS
## Simple Storage Service(S3)
特徴
データ保存形式
オブジェクトの構成
S3のオブジェクトは以下のような要素で構成されている
- Key
- オブジェクト名前
- バケット内のオブジェクトは一意に識別する
- Value
- データそのものであり、バイト値で構成される
- バージョンID
- バージョン管理に用いるID
- メタデータ
- オブジェクトに付随する属性の情報
- サブリソース
- バケット構成情報を保存及び管理する為のサポートを提供

- バケット構成情報を保存及び管理する為のサポートを提供
S3の整合性モデル
- S3は高い可用性を実現するため、データ更新・削除には結果整合性モデルを採用
- 同時書き込みはタイムスタンプ処理を実施
S3のアクセス管理
S3のアクセス管理は用途に応じて方式を使い分ける
S3のアクセス管理
S3はインターネットからパブリックアクセスの設定が可能
S3の機能
S3アクセスポイント
S3上の共有データセットを使用するアプリケーションへの大規模なデータアクセス管理を実施
- アクセスポイントの作成
- アプリケーション向けにS3パケット内にアクセスするためのアクセスポイントを作成
- アクセス制限設定
- VPCアクセス制限設定
- アクセス管理の実行
- アプリケーション向けのアクセス対象を拡大・制限するなど容易にコントロール可能
S3アクセスアナライザー
アクセスポリシーに沿っているかを確認し、不正なアクセスが発生していないか、アクセスポリシーを管理する機能
ライフサイクル管理
バケット内のオブジェクト単位でストレージクラスの変更や削除時期などを設定することができる
レプリケーション
リージョン間を跨ぐクロスリージョンレプリケーションにより耐障害性を高める
バージョン管理
ユーザーによる誤操作でデータ削除などが発生してもバージョンから復元できる
バックアップ
Glacierを利用してバックアップと復元を実施可能
アーカイブ
- 複数リージョンをレプリケートすることが可能
- S3オブジェクトデータをライフサイクル設定によりGlacierに移動 リストア
- バージョン管理機能によって削除されたデータを復元するのが基本
利用状況の確認
S3の利用状況やS3のイベント発生を確認することができる
CORS
クロスオリジンリソースシェアリング(CORS)により特定のドメインにロードされたアプリケーションが異なるドメイン内のリソースと通信する方法

マルチアップロード
大容量オブジェクトをいくつかに分けてアップロードする機能
バッチオペレーション
S3オブジェクトの大量データに対して一括処理を実行することが可能
- ジョブ
- ジョブはS3バッチオペレーションの機能の基本単位でジョブを作成することがバッチオペレーションを作成
- ジョブにはオブジェクトのリストに対して指定された操作を実行するために必要な全ての情報を登録
- S3バッチオペレーションにオブジェクトのリストを渡し、それらのオブジェクトに対して実行するアクションを指定
- マニフェスト
S3の用途
大量データを長期保存するという観点から用途を検討する
コンテンツ配信・保管
CMSから画像等のコンテンツデータの保管先にS3を利用する

ログ・バッチの保管場所
ログファイルやバッチファイルの保存場所としてS3を利用する

バックアップ・ディザスタリカバリ
バックアップの中長期の保存場所としてS3を利用する
WEBの静的ホスティング
S3のみで静的なWEBサイトをホスティングして構築可能
データレイク
S3はデータレイクとしてデータ活用のハブとして利用できる
AWS CLI
AWS CLIはコマンドラインから複数のAWSサービスを制御・管理することが可能
S3の外部接続
標準的なストレージプロトコルを利用して外部システム環境とAWSのストレージサービスを接続するサービス
- AWSが有する機能や性能を活用できることが大きな利点
- データ移転や保存などAWSストレージを利用したい場合に用いる
Storage Gatewayのタイプ
- 利用するデータに応じて3つのゲートウェイを利用する
Amazon S3 Glacier
バックアップなど中長期保存用のS3よりも安価なストレージ
- S3と同じ耐久性で値段が安い
- 一方で、データ取得などの迅速性がない
Glacierの仕組み
S3とは異なり、ボールトとアーカイブという単位でデータを保存
AWSアーキテクチャ設計の基礎
AZの選択
- 1つのリージョンにつき2つのAZを利用してアーキテクチャを設計することが基本(3つ以上はコスト効率が低下する)
- マルチAZにサーバーやDBの冗長構成を確立させることで高い可用性を実現する

VPC

サブネットの分割
- サブネットはCIDR範囲で分割したネットワークセグメント
- サブネットはインターネットアクセス範囲を定義するためlに利用する
サブネットのサイズは「/24」以上の大きいサブネットを推奨
パブリックサブネット
- インターネットと接続が必要なリソースを揃える
- インターネットとのアクセス制御に利用する
- 例
- ウェブアプリケーションのインターネットアクセス制御
プライベートサブネット
1つのAZに対して1つのパブリックサブネットと1つのプライベートサブネットが基本
- プライベートサブネットに多くのIPアドレスを割り当てる
Well-Archtected Framework
- 5つの設計原則
- Reliability(信頼性)
- Perfomance Efficiency(パフォーマンス効率)
- Security(安全性)
- AWS内のデータ・システム・アセットの保護とモニタリングによりセキュリティを高める
- 設計事項
- セキュリティの基本対応領域は以下の4つ
- Cost Optimization(コスト最適化)
- Operational Excellence(運用上の優秀性)
- 運用上の優秀性とは計画変更が起こった場合や予期せねイベントの発生時において、自動化された運用実務及び文書化されテストされレビューされた手順があること
- 設計事項
- コードに基づく運用実施
- ビジネス目的に沿った運用手順
- 定期的かつ小規模で増加的な変更実施
- 予期せねイベントへの応答テスト
- 運用イベントと障害からの学習
- 運用手順を最新のものに保持すること
- 運用上の優秀性の基本対応領域は以下の3つ
AWSのベストプラクティス
- スケーラビリティの確保
- 環境の自動化
- システムの安定性・整合性及び組織の効率性を改善するための主要プロセスを自動化する
- 関連する主要サービス
- Cloud Formation
- Codeシリーズ
- ECS
- Elastic Beastalk
- OpsWorks
- Cloud Watch
- 使い捨てリソースの使用
- サーバーなどのコンポーネントを一時的なリソースとして利用・設計する
- 関連する主要サービス
- EC2
- Auto Scaling
- コンポーネントの疎結合
- サーバーではなくサービス(サーバレス)
- 最適なデータベース選択
- ワークロードに応じた最適なデータベース技術を利用する
- 関連する主要なサービス
- Redshift
- RDS
- Dynamo DB
- Aurora
- Elastic search
- 増大するデータ量対応
- IOT/ビックデータなどで絶えず増加するデータの保持を効率的に実施する
- 関連する主要サービス
- S3
- Kinesis
- Glacier
- 単一障害点の排除
- コスト最適化
- リソースが適切なサイズから必要に応じたスケールアウト・スケールインの実施と最適な料金プランの選択
- キャッシュの利用
- 繰り返し取り出すデータやコンテンツについてはキャッシュを利用する構成
- 関連する主要サービス
- Cloud Front
- Elastic Cache
- セキュリティの確保
- 全てのレイヤー・業界・リソース内/外においてセキュリティを実装する

- 全てのレイヤー・業界・リソース内/外においてセキュリティを実装する
信頼性の設計
高可用性
- 高可用性とはアーキテクチャにより自動でシステムのダウンタイムを限りなくゼロにすること
- AWSアーキテクチャ設計において高可用なシステムを実現するかが重要なポイントとなる
- 高可用なサービス利用
- 高可用なアーキテクチャ設計
- 基本機能はユーザー側で高可用な設計をする必要がある
- 高可用性の非機能要件
ELB(Elastic Load Balancing)
- マネージド型のロードバランシングサービスでEC2インスタンスの処理を分散する際に標準的に利用する
- 特徴
主要機能
ELBの種類
- CLB
- 初期に提供されたELB
- 標準的なL4/L7におけるロードバランシングが可能だが複雑な設定はできない

応用情報技術者
CPU
コンピュータはプログラムという名のソフトウェアがハードウェアに「こう動け」と命令することで動く機会。その命令を理解して必要が演算をしたり実際の処理を行うのはCPUの役割。
5大装置とそれぞれの役割
- 制御装置:プログラムの命令を解釈してコンピュータ全体の動作を制御(CPU)
- 演算装置:四則演算をはじめとする計算や、データの演算処理を行う。(CPU)
- 記憶装置
- 主記憶装置:動作をするために必要なプログラムやデータを一時的に記憶する装置(メモリ)。コンピュータの電源を切るとその内容は消える
- 補助記憶装置:プログラムやデータを長期に渡り記憶する装置。長期保存を前提としているので主記憶装置のようにコンピュータの電源をきることで内容が破壊されたりすることはない。(ドライブ) 入力装置:コンピュータにデータを入力するための装置。(マウス、キーボード) 出力装置:コンピュータのデータを出力するための装置(ディスプレイなど)
ノイマン型コンピュータ
補助記憶装置 → 主記憶装置 → CPUで実行
- プログラム内蔵方式:実行時にはプログラムをあらかじめ主記憶装置上に読み込んでおく
- 逐次制御方式:命令を1つずつ取り出して、順番に実行していく方式
CPUの命令実行手順とレジスタ
CPUが命令を実行するために取り出した情報はレジスタと呼ばれるCPU内部の記憶装置に保持する
レジスタの種類とそれぞれの役割
| 名称 | 役割 |
|---|---|
| プログラムカウンタ | 次に実行する命令が入っているアドレスを記憶するレジスタ |
| 命令レジスタ | 取り出した命令を一時的に記憶するためのレジスタ |
| インデックス(指標)レジスタ | 取り出した命令を一時的に記憶するためのレジスタ |
| ベージレジスタ | アドレス修飾に用いるためのレジスタで連続したデータの取り出しに使うための増分値を保持する |
| アキュムレータ | 演算の対象となる数や、演算結果を記憶するレジスタ |
| 汎用レジスタ | 特に機能していないレジスタ。一時的なアタイの保持や、アキュムレータなどの代用に使用する |
命令の実行手順①「命令の取り出し(フェッチ)」
最初に行われるのは命令の取り出し(フェッチ)作業
- 取り出すべき命令がどこにあるかは、プログラムカウンタが知っている
- プログラムカウンタの示すアドレスを参照して命令を取り出し、それを命令レジスタに記憶させる
- 取り出し終わったら次の命令に備えてプログラムカウンタの値を1つ増加させる
命令の実行手順②「命令の解読」
先ほど取り出した命令の解読作業に入る
命令レジスタに取り出した命令は次の構成でできている
- 命令部:実行させたい命令の種類を示すコード番号が入っているところ
オペランド部:処理対象となるデータを納めたメモリアドレスなどが入っているところ
命令部の中身が命令デコーダと送られる。
- 命令デコーダは命令部のコードを解読して必要な装置に制御信号を送る(例えば命令が演算処理とかだった場合は、「加算処理がきたよー」などと演算装置(ALU)に伝えたりする)
命令の実行手順③「対象データ(オペランド)読み出し」
仮に命令が加算などの演算処理だったとするとその演算の元となる数値が必要。それを読み取ってくる作業。
命令の実行手順④「命令実行」
あとは命令を実行するだけ。仮に命令が演算処理だったとすると、演算装置がえいやと計算して終了
- 汎用レジスタから処理対象のデータを取り出した演算
- その後、演算結果を書き戻して終了
- 終わったら実行手順①に戻って一連の手順を繰り返す
機械語のアドレス指定方式
- 計算によって求めた主記憶装置上のアドレスを実効アドレス(もしくは有効アドレス)と呼ぶ.
- コンピュータの理解できる言葉が機械語であり、0と1で構成されている。
- 命令レジスタに取り出しいてた命令も機械語
- 命令は「命令部」「オペランド語」で構成されており、「何を(オペランド部)どうしろ(命令部)」という記述になっている
- 「オペランド部」の部分は必ずしも「メモリのアドレス」が入っているとは限らない。何らかの計算によって入っている可能性もある。
- 何らかの計算によってアドレスを求める方式をアドレス修飾と呼ぶ
CPUの性能指標
CPUの性能をあらわすための指標値に以下がある
- クロック周波数
- 周期信号の繰り返し数。コンピュータには同調をとるための周期信号があるが、これが一秒間に何回チクタクできるかを表している。
- CPI(Clock cycles Per Instruction)
- 信号何周期分で1つの命令が実行できるかをあらわしている
- MIPS(Million Instruction Per Second)
- 1秒間に実行できる命令の数。
クロック周波数は頭の回転速度
- コンピュータには色んな装置が入っているが、そればバラバラに動いていてはまともに動作しない
- 「クロック」と呼ばれる周期的な信号に合わせて動くのが決まり事になっており、装置同士がタイミングを同調できるようになっている
- CPUもクロックという周期信号に合わせて動作を行う
- チクタクチクタクの繰り返される信号に合わせて動くからチクタクという1周期の時間が短ければ短いほど、より多くの処理ができる
- クロックが1秒間に繰り返される回数のことをクロック周波数と呼ぶ。単位はHz
CPUの高速化技術
複数の命令を並行して実行させることができれば回路の遊び時間をなくし、処理効率を高めることができる
パイプライン処理
- パイプライン処理
- 次から次へと命令を先読みし並行で処理する
- 分岐命令などが出てきた場合は先読み分が無駄になってしまうこうともある
パイプラインをより高速化をさらに推し進める手法として以下がある
- スーパーパイプライン
- 各ステージ(命令実行順序の単位)の中身をさらに細かいステージに分割することにより、パイプライン処理の効率アップを図るもの
- スーパースカラ
- パイプライン処理を行う回路を複数持たせることで全く同時に複数の命令を実行できるようにする
VLIW
- VLIW(Very Long Instruction World)
CISCとRISC
CPUには高機能な命令を持つCISCと、単純な命令のみで構成されるRISCという2つのアーキテクチャがある。アーキテクチャというのは基本設計とか設計思想という意味の言葉。
http://seskillup.jp/risc-cisc-cpu/
並列処理
- 複数のプロセッサ(CPU)を協調して処理にあたらせる技術のことを並列処理と呼ぶ。
- 単独のCPU内で果たすことができる性能向上には限界が近づきつつあり、複数のCPUを協調させて動作を行う並列処理の重要度は増す一方
- ひとつのコンピュータシステム上に複数のCPUを搭載するマルチプロセッサシステムは各CPUに対して処理を分散させることでCPU単独ではなくシステム全体でパフォーマンスの向上を図る
- 処理を分散させる方式として以下がある
- マルチコアプロセッサ
- CPUパッケージ内に複数のコア(CPUの中核で実際に処理を担当するところ)を持たせたもの
マルチプロセッサと主記憶装置
複数のCPUが強調動作を行うにあたり、主記憶装置との関係は重要な問題。(入手力がぶつかる恐れがあるから) この主記憶装置との結合方法によってマルチプロセッサシステムを分類したものが、密結合型と疎結合型。
- 密結合マルチプロセッサ
- 複数のプロセッサが主記憶装置を共有し、それを単一のOSが制御する方式。
- OSによってタスクが分散され処理能力の向上が図れるが、共有した主記憶装置へのアクセルが競合した場合、処理効率が低下する
- 疎結合マルチプロセッサ
- 複数のプロセッサそれぞれに対して独立した主記憶を割り当てる方式。各プロセッサ毎にOSが必要となる。
- クラスタシステムと言われるものがこの1種で多くの場合は独立したコンピュータ同士を通信路でつなぎ、その全体を一つのシステムとして稼働させる
メモリ
メモリの分類
メモリはコンピュータの動作に必要がデータを記憶する装置。 RAMは読み書き可で揮発性、ROMは読み出し専用で不揮発性が特徴。
RAMの種類いろいろ
RAMとはその名の通り「ランダムに読み書きできるメモリ」のこと。 RAMはさらに主記憶装置に使われるDRAMとキャッシュメモリに使われるSRAMの2種類に分かれる。
- DRAM(Dynamic RAM)
- 安価で容量が大きく、主記憶装置に用いられるメモリ。
- 読み書きはSRAMに比べて低速。
- 記憶内容を保つためには、定期的に内容を再書き込みするためリフレッシュ動作が欠かせない
- SRAM(Static RAM)
ROMの種類いろいろ
ROMもその名の通り「リードオンリー(読み出しだけ)なメモリ」のこと。ただ「基本的には読み出しだけ」というだけで実は専用の機器を使うと記憶内容の消去と書き込みができるPROMという種類も存在する。 デジタルカメラなどで利用されているメモリカード(SDカードなどは)この一種。フラッシュメモリとも呼ばれる。
主記憶装置と高速化手法
記憶装置間の速度ギャップを埋めて待ち時間によるロスを防ぐための手法がキャッシュ。
- レジスタとメモリ、メモリとハードディスクの間には「越えられない壁」といっても良いくらいの速度差がある
- 装置間の速度ギャップを緩和させるために用いる手法でレジスタとメモリの間に設けるキャッシュメモリや、メモリとハードディスクの間に設けるディスクキャッシュなどがある。
キャッシュメモリ
- CPUはコンピュータの動作に必要なデータやプログラミムをメモリ(主記憶装置)との間でやりとりをする。
- しかし、CPUと比べるとメモリは非常に遅いので読み書きの度にメモリへアクセスすると待ち時間ばかり発生する。
- メモリとCPUの間により高速に読み書きできるメモリを置いて速度差によるロスを吸収させる。これをキャッシュメモリと呼ぶ。
- キャッシュメモリはCPUの中に存在する
- CPUに内蔵できる容量はごく小さいものになるから「それよりも低速だけど、その分容量を大きく持てる」メモリをCPUの外側にキャッシュとして増設したりすると、よりキャッシュ効果が期待できる。この時用いるのがSRAM。
ディスクキャッシュ
プログラムの局所参照性
局所参照性とは、資源への参照やアクセスが一部分に偏ったり集中すること。プログラムに局所参照性があるからキャッシュが有用であること言える。
- 時間的局所性
- 最近使われたデータほど、再度アクセスされる可能性が高い
- 空間的局所性
- 使われたデータの近くにあるデータは再度アクセスされる可能性が高い
- 逐次的局所性
- 使われたデータの隣は逐次アクセス(シーケンシャルアクセス)される可能性が高い
主記憶装置への書き込み方式
- キャッシュメモリは読み出しだけでなく、書き込みでも使用される。
- ただし、読み出しと違って書き込みの場合は、更新した内容をどこかのタイミングで主記憶装置にも反映する必要がある
- 主記憶装置を書き換える方式にはライトスルー方式とライトバック方式の2つがある
ヒット率と実行アクセス時間
キャッシュメモリの容量は小さなものなので、目的とするデータが必ずそこに入っているとは限らない。この「目的とするデータがキャッシュメモリに入っている確率」のことをヒット率と呼ぶ。
キャッシュメモリの割り当て方式
主記憶上のデータはブロックという一定長の単位ごとにキャッシュメモリへの割り当てが行われる。この時ブロックをどの場所に格納するか管理する方式として次の3つがある
- ダイレクトマッピング方式
- 1つのメモリブロックをキャッシュ内の単一のロケーションに割り当てる方式。
- 具体的にはハッシュ演算と呼ばれる一定の計算式によって主記憶のブロック番号からキャッシュ内のロケーションを求め、データの割り当てを行う
- フルアソシアティブ方式
- セットアソシアティブ方式
- メモリブロックをキャッシュ内の2つ以上の配置可能なロケーションに割り当てる方式
- キャッシュメモリとメモリブロックと対応付された複数のセットにわけ、そのセット内ならどこへでも空いている場所を使用することができる
- 前述の2方式の折衷案的な割り当て方法で、現在一般的に用いられている手法
ハードディスクとその他の補助記憶装置
ハードディスクの構造と記録方法
ハードディスク(磁気ディスク装置)は高速回転しているディスクに磁気ヘッドを使って情報を読み書きしている。
- ハードディスクの中身
- ディスク
- 金属やガラスでできている硬い円盤
- 表面に磁性体が塗布されていて、これを磁化することで情報を記録
- アクセスアーム
- 先端に磁気ヘッドがついてるアーム
- ディスク上の目的地まで磁気ヘッドを運ぶのがお仕事
- 磁気ヘッド
- アクセスアームの先端についてる微笑な電磁コイル
- ディスク表面の磁性体を磁化させたり読み取ったりする。
- ディスク
セクタとトラック
https://wa3.i-3-i.info/diff139data.html
フラグメンテーション
ハードディスクに書き込みや消去を繰り返していくと、連続した空き領域が減り、ファイルが断片化していく。
- ハードディスクの空きが十分にあれば、ファイルは通常連続した領域に固まって記録される
- ファイルの書き込みと消去を繰り返すとプラッタ上の空き領域はどんどん確保できないから途中からあちこち離れが場所に書くようになる
- こうなるとファイルを一つ読み書きするだけでもあちこちのトラックへ磁気ヘッドを移動させなきゃいけない
「ファイルがあちこちに分かれて断片化してしまう」状態のことをフラグメンテーション(断片化)と呼ぶ。
デフラグで再整理
- フラグメンテーションを解消するために行う作業をデフラグメンテーションと呼ぶ。
- デフラグは断片化したファイルのデータを連続した領域に並べ直してフラグメンテーションを解消している。
バスと入出力デバイス
バスアーキテクチャ
- コンピュータの中でデータが運ばれる経路のことを「バス」と呼ぶ。
- 内部バス
- CPU内部の機器を接続するバス(ALU、レジスタ)
- 外部バス
- 外部の機器を接続するバス
- CPUとメモリやHDDを接続する高速なもの、キーボードやマウス、ディスプレイといった入出力装置を接続する低速なもの両方ある
- 上述の2つはブリッジというコントローラによって接続
- 内部バス
パラレル(並列)とシリアル(直列)
バスはデータを転送する方式によってパラレルバスとシリアルバスに分かれる。 複数の信号を1回で送れるパラレルバスが高速とされていたが、高速化を突き進めていくにつれ信号間のタイミングを取ることが難しくなり、現在はシリアルバスで高速化を図るのが主流。
入出力制御方式
コンピュータは様々な機器とデータのやりとりを行う。この時の入出力を制御するやり方が入出力制御方式
- プログラム制御方式(直接制御方式)
- 入出力装置からメモリへのデータ転送をCPUが直接制御する方式
- データの転送は随時CPUのレジスタを経由して行われる
- 低速な入出力処理にCPUがかかりっきりになってしまうと処理効率の面でよろしくない。
- DMA(Direct Memory Access)制御方式
- 入出力装置からメモリへのデータ転送をCPUを介さずに行う制御方式
- DMA制御方式は専用の制御回路(DMAコントローラ)がメモリと入出力装置間のデータ転送を行う
- CPUがDMAに命令を行い、DMAがストレージとメモリの間のデータ転送を管理する
- チャネル制御方式
- DMA制御方式をさらに拡張したもの。
- 入出力制御用のCPUなどを備えたチャネルという専用装置がメモリと入出力装置間のデータ転送を自律的に行う
オペレーティングシステム
OSの仕事
- OSとはオペレーティングシステムの略。コンピュータの基本動作を実現するソフトウェア。
- OSはコンピュータ内部のハードウェアや様々な周辺機器を管理する他、メモリ管理、ファイル管理、そしてワープロなどのアプリケーションに実行機械を与えるタスク管理などをしている
ソフトウェアの分類
ソフトウェアの分類は以下である
- システムソフトウェア
- 応用ソフトウェア
基本ソフトウェアは3種類のプログラム
基本ソフトウェア
- 制御プログラム
- ハードウェアを管理して応用ソフトウェアやミドルウェアからコンピュータを効率的利用できるようにしているソフトウェア
- 一般にこのプログラムのことをカーネルと呼ぶ
- カーネルにはメモリ管理やプロセス管理などに機能を限定したマイクロカーネルと多くの機能を網羅したモノシリックカーネルがある
- ジョブ管理、タスク管理、記憶管理、データ管理などを行う
- 言語処理プログラム(言語プロセッサ)
- サービスプログラム
- コンピュータの機能を補う、補助的なプログラムのことでユーティリティ
- ファイル圧縮プログラムなどが該当
ジョブ管理
利用者から見た仕事の単位がジョブ。ジョブを効率よく処理していけるようにOSは実行スケジュールを管理する
- バッチ処理で複数のジョブを登録してコンピュータに空き時間を作らず次々と働かせる仕組み、それがジョブ管理という
- 主な役割は複数のジョブをスケジューリングし、実行単位であるジョブステップに分解して個々の実行を監視・制御するというものなる。
ジョブ管理の流れ
ジョブ管理はカーネルが持つ機能のひとつ。この機能で利用者との橋渡しをするのがマスタスケジュールという管理プログラム。利用者はこの管理プラグラムに対してジョブの実行を依頼する。
- マスタスケジュール
- ジョブの実行をジョブスケジューラに依頼
- 自身は実行状態の監視に努め、必要に応じて各種メッセージを利用者に届ける
- ジョブスケジューラ
スプーリング
- CPUと入出力装置(印刷機など)とは処理速度に大きな差がある。
- 間に高速な磁気ディスクを蓄えるようにしCPUは入出力装置を待たなくても済むようにする。
- 「低速装置とのデータのやりとりを、高速な磁気ディスクを介して行うことで処理効率を高める方法」をスプーリングと呼ぶ。
タスク管理
- コンピュータから見た仕事の単位がタスク
- ジョブステップの実行準備が整うことでタスクが生成
- タスクはコンピュータが「実行中のプログラムである」と識別する仕事
- プロセスとも呼ばれる(厳密に言うと両者は違う)
- 単純に言うとタスクというのはコンピュータでコマンドを叩いたりアプリケーションアイコンをダブルクリックしたりして、プログラムがメモリにロードされて実行状態に入ること
タスクの状態移遷
- 実行可能状態
- いつでも実行が可能な、CPUの使用権が回ってくるのを待っている状態
- 生成直後のタスクはこの状態になってCPUの待ち行列に並んでいる
- 実行状態
- CPUの使用権が与えられて、実行中の状態
- 待機状態
- 入出力処理が発生したので、その終了を待っている状態
ディスパッチャとタスクスケジューリング
ディスパッチャ
- 実行可能状態に順番待ちしているタスクに「次が出番」とCPUに使用権を割り当てるの管理プログラム
- ディスパッチャは日本語で「派遣する人」「配車係」
タスクスケジューリング
- 「どのタスクに使用権を割り当てるのか」を決めるための順序
- 以下のものがある
- 到着順方式
- 実行可能状態になったタスク順にCPUの使用権を割り当てる方式
- タスクに優先度の概念がないので、実行の途中でCPU使用権が奪われることはない(ノンプリエンプションと言う)
- 優先度順方式
- タスクにそれぞれ優先度を設定し、その優先度が高いものから実行していく方式
- 実行中のタスクよりも優先度の高いものが待ち行列に追加されると実行の途中でCPU使用権が奪われる(プリエンプションと言う)
- 動的優先順位方式
- 基本的な動きは上記優先度順方式と同じ
- タスクがCPU使用権の割り当てを受けるまでの待ち時間の長さによってその優先度を徐々に上げていく
- タスクの優先度を引き上げて実行の可能性を調整することをエージングと呼ぶ
- ラウンドロビン方式
- CPUの使用権を一定時間ごとに切り替える方式
- 実行可能状態になった順番でタスクにCPUが与えられるが、規定の時間内になっても処理が終わらない場合次のタスクに使用権が与えられ、実行中だったタスクは一番後回しにされる
- 多重待ち行列
- ラウンドロビン方式に優先順位を加味させた方式
- 処理時間順方式
- タスクの処理時間がより短いものから順に処理をしていく方式
- イベントドリブン方式
- マウスによる入力など環境の変化をタスクに切り替えのきっかけとしてCPUの使用権を切り替える方式
- 到着順方式
マルチプログラミング
タスク管理の役割はCPUの有効活用に尽きる。つまり、CPUの遊休時間を最小限にとどめることが大事
割込み処理
実行中のタスクを中断して別の処理に切り替え、そちらが終わるとまた元のタスクに復帰するという処理のことを割込み処理と呼ぶ。マルチプログラミングには必須の仕組み
- 割込み処理は2つに分かれる
- 内部割込み
- 外部割込み
- 入出力割込み
- 入出力装置の動作完了時や中断時に生じる割込み
- 機械チェック割込み
- 電源の異常や主記憶装置の障害など、ハードウェアの異常発見時に生じる割込み
- コンソール割込み
- オペレータ(利用者)による介入が行われる時に生じる割込み
- SVC
- 入出力割込み
リアルタイムOS
時間的制約を守ることを最優先とした、組み込み用途向けの処理を行うOS - 例えば、自動車のABS(アンチロックブレーキングシステム)などに使われている
タスクの排他/同期制御
タスクが複数同時実行される環境では互いの干渉を避ける排他制御や、強調動作のための同期制御が欠かせない
- タスクはその生成時にOSから独立した記憶領域に割り当てられて動作
- この記憶領域には以下が含まれる(詳しくはプログラムの作り方で解説)
- そのプログラム自身を格納するための領域
- タスク内で用いられる変数や関数呼び出しに必要な情報などを格納するスタック領域
- メモリを確保する命令を用いることで都度必要に応じて動的に確保するヒープ領域が含まれる
排他制御が必要な理由
2つタスクが同時に進んでおり、同じ値を参照し更新したら不都合が起きるため排他制御が必要。 片方の処理が終了してからもう片方が処理を行う
値を読む ⇨ 処理をする ⇨ 値を更新する
セマフォ
- クリティカルセクション
- 一連の処理の中で2つ以上のタスクが同時に資源を奪い会うことで処理に不整合が生じる箇所
値を読む ⇨ 処理をする ⇨ 値を更新するの流れ
- セマフォ(概念)
デッドロック
- 排他制御において、複数の資源をそれぞれのタスクが無秩序にロックしていくと互いに相手のロックしている資源の解除もちに入り処理が進行しなくなる現象
- これを避けるためには資源のロックを順序を両方のタスクで同じに揃えることが必要
同期制御とイベントフラグ
- タスク同士が互いに依存関係を持ち、一方の処理を待って他方が実行を再開するといった強調動作も行われる
- このようなタスク同士を強調させるために実行タイミングを図る仕組みを同期制御と呼ぶ
- タスク間の同期方法としてもっとも基本的な手法がイベントフラグ
- イベントフラグはカーネルの監視下に置かれたビットの集合で1つのビットが1つのイベントを表すフラグとなっている
タスク間の通信
タスク間の通信用いられる代表的な手段は以下のものがある
- 共有メモリ
- メモリ上に複数のタスクから利用できる記憶領域を設けてデータ交換を行う
- メッセージキュー
- キューというのは簡単に言えば待ち行列のこと
- メッセージ処理用のキューにタスクからのデータをメッセージとして送信し、受信側はこのキューを介してデータを受け取る
- パイプ
- 仮想的なパイプを通してデータをやり取りする仕組み
- あるタスクの出力をもう一方のタスクに入力して接続し、データを転送
実記憶管理
限られた主記憶空間を、効率良く使えるようプログラムに割り当てるのが実記憶管理の役割
- プログラムを主記憶装置(メモリ)にロードする際に、プログラムをロードした時の割り当て方がへっぽこだと主記憶の容量が十分にあったとしても容量が活用できなくなる
固定区画方式
- 固定区画方式は主記憶に固定長の区画(パーティション)を設けて、そこにプログラムを読込む管理方式
- 単一区画方式と多重区画方式がある
- 単一区画方式
- ひとつのプログラムしかロードできないのでマルチプログラミングには使えない
- 多重区画方式
- 区画ごとにプログラムをロードすることができる
- 単一区画方式
- 単純な仕組みなので記憶管理は簡単
- 区画のスペースが決められている(8MBなど)
- 区画内に生じた余りスペースは使用できず、区画サイズ以上のプログラムを読込むこともできない
- 主記憶の利用効率はあまりよくない
可変区画方式
主記憶を最初に固定長に区切ってしまうのではなく、プログラムをロードするタイミングで必要なサイズに区切る管理方式が可変区画方式
- プログラムが必要とする大きさで区画を作り、そこにプログラムをロードする
- 固定区画方式より主記憶の利用効率はよくなる
フラグメンテーションとメモリコンパクション
- 可変区画方式だと主記憶上にプログラムを隙間なく詰め込んで実行することができるが、必ずしも順番にプログラムが終了するとは限らない
- 主記憶の空き容量自体がプログラムの実行に足るサイズでもそれを連続した状態で確保することはできない
- ↑の現象をフラグメンテーション(断片化)と呼ぶ
- フラグメンテーションを解消するにはロードされているプログラムを再配置することによって細切れ状態にある空き領域を連続したひとつの領域にしてやる必要がある
- この操作をメモリコンパクション、ガーベージコンパクションと呼ぶ
オーバーレイ方式
- 実行したいプログラムのサイズが主記憶の容量を超えていたらロードしようがない
- これを可能にするための工夫がオーバーレイ方式
- プログラムをセグメントという単位に分割しておいて、その時に必要なセグメントだけを主記憶上にロードして実行する
- プログラムは複数の機能が組み合わさった集合体
- しかし常にその全機能が使われているわけではない
- なので処理の過程で必要とされる機能だけを主記憶上へロードすることにしてやれば、占有する場所を減らすことができる
スワッピング方式
- マルチプログラミング環境では優先度の高いプログラムによる割込みなどが発生した場合に現在実行中のものを一旦中断させて切り替えを行う
- このような時は優先度の低いプログラムが使っていた主記憶領域の内容を一旦補助記憶装置に丸ごと退避させることで空き領域を作る(スワップアウトと呼ぶ)
- 退避させたプログラムに再びCPUの使用権を与えられる時は、退避させた内容を補助記憶装置から主記憶へとロードし直して中断箇所から処理を再開する(スワップインと呼ぶ)
- スワップアウトとスワップインを合わせた、このような処理ことをスワッピングを呼ぶ
- スワッピングが発生すると主記憶の代用として低速な補助記憶装置へのアクセスを行うことになるので処理速度が極端に低下
再配置可能プログラムとプログラムの4つの性質
再配置可能プログラミングなら主記憶上のどこに配置しても問題なく実行できる
- ベースアドレス方式「プログラムが主記憶上にロードされた時の先頭アドレスからの差分」を使って命令やデータの位置を指定している
- このような性質を持つプログラミングを再配置可能プログラムと呼ぶ
再配置可能(リロケータブル)
- 主記憶上のどこに配置しても実行することができる性質
- ベースアドレス指定方式を用いることによってロードされた位置に応じてメモリアドレスの情報を補正
再使用可能(リユーザブル)
- 主記憶上にロードされて処理を終えたプログラムを再ロードすることなく、繰り返し実行(毎回正しい結果が得られる)できるという性質
- 使用した変数の値をプログラムの最初か最後に初期化しておくことで繰り返しの実行に備えている
再入可能(リエントラント)
- 再ロードすることなく繰り返し実行できる再使用可能プログラムにおいて複数のタスクから呼び出しても互いに干渉することなく同時実行できるという性質
- プログラムの中が処理の手順を定義した手続き部分とそこで用いるデータ部分に分かれている
- このデータ部分をタスクごとに持つことで互いに干渉せず並行して動作できる
再帰的(リカーシブ)
- 実行中に自分自身を呼ぶ出すことができるという性質
仮想記憶管理
仮想記憶は、主記憶や補助記憶の存在を隠蔽することで広大なメモリ空間を自由に扱えるようにする
- 仮想的なメモリ空間を作ってプログラムに使わせるのが仮想記憶
- その実体は主記憶装置と補助記憶装置を合わせて作ったメモリ空間だが、プログラムからは大量の主記憶装置があるのように見える
なんで仮想記憶だと自由なの?
- 実記憶管理だとフラグメーションなどが起きてロードスペースがなくなることがあったりする
- 仮想記憶では仮想的な記憶領域なので物理的な実体というものがない
- 実際のデータは実記憶上に記憶される
- 仮想記憶というのは「実記憶などの物理的な存在を隠蔽して、仮想空間にマッピング(対応付けとか割り当てという意味)してみせる」ための技術
- つまり仮想記憶でロードした8MBを実記憶上で4MB, 4MBに分けることでロードすることも可能
- 仮想アドレスから実アドレスへの変換処理はメモリ変換ユニットというハードウェアが担当する
- この仕組みを動的アドレス変換機構と呼ぶ
実記憶の容量よりも大きなサイズを提供する仕組み
- 仮想記憶に置かれたデータは実際にはその裏で実記憶へと記憶される(これだと実記憶の容量を超えるサイズのデータは扱えない)
- 実は実記憶だけでなく、補助記憶(ストレージ)にもマッピングすることができる
- 仮想記憶では補助記憶装置もメモリの一部と見なすことで実記憶の容量よりも大きなサイズの記憶空間を提供できる
仮想記憶を実現している仕組み
仮想記憶の実装方式には仮想アドレス空間を固定長の領域に区切って管理するページング方式と、可変長の領域に区切って管理するセグメント方式の2つがある
- ページング方式
- ページング方式ではプログラムを「ページ」という単位に分割して管理する
- プログラムというのはいろんな機能があるのでいつも全てを必要とされるわけではない
- 現在のOSではデマンドページという「実行に必要なページだけを実記憶に読込ませる」方式が主流
- 仮想記憶と実記憶との対応付はページテーブルという表によって管理される
- ページテーブルを確認して「実記憶に存在しない」となった場合は実記憶へのページ読み込みが発生
- ページイン:補助記憶から実記憶への読み込み
- ページアウト:実記憶から補助記憶へとページを追い出すこと
- 実記憶の容量が少ないとページの置き換えを必要とする頻度が高くなり、システムの処理効率が極端に低下する。これをスラッシングと呼ぶ
- ページテーブルを確認して「実記憶に存在しない」となった場合は実記憶へのページ読み込みが発生
プログラムの作り方
言語プロセッサ
翻訳作業を行うプログラムを総称して言語プロセッサと呼ぶ
- プログラミング言語は低水準言語と高水準言語の2つに分けることができる
- 主要な言語のプロセッサは次の3つがある
インタプリタとコンパイラ
インタプリタ方式
- ソースコードに書かれた命令を1つずつ機械語に翻訳しながら実行
- 逐次翻訳していく形であるため、作成途中のプログラムもその箇所まで実行させることができるなど「動作を確認しながら作成する」といったことが容易に行える
- ただし、実行速度はそれなりに遅い
コンパイラ方式
特殊な言語プロセッサ
- プリコンパイラ
- 高水準言語で付加的に定義された機能と文法に従ってコーディングされたプログラムを元の高水準言語を使用したプログラムへと変換するもの
- コンパイルの前処理として行う
- クロスコンパイラ
- コンパイラが動作している環境とは異なるプラットフォーム向けの目的プログラムを生成
- 例:windows OS上でコンパイルして、スマホのOS上で動かすための目的プログラムを作ったりする
- エミュレータ
- システム上で他のOSやCPUの機能を模倣する環境を実現するプログラム
- 異なるプラットフォーム向けのプログラムをその命令を解読しながらそのまま実行させる
- ジェネレータ
- パラメータを与えるだけで自動的にプログラムを生成
コンパイラ方式でのプログラム実行手順
リンカというプログラムが実行に必要なファイルを全てくっつけることで実行可能なファイルは生成される
コンパイラの仕事
コンパライの仕事はプログラミング言語を使って書いたソースコードを翻訳して機械語のプログラムファイルにすること
コンパイラの中ではソースコードを次のように処理することで目的プログラムを生成する
- 字句解析
- ソースコードに書かれているプログラムコードを字句(トークン)単位に分解
変数A = 変数B + 10という文があったら変数A=変数B+10と分ける
- 構文解析
- 分解したトークンをプログラム言語の構文規則に従って解析
- 解析して構文木と呼ばれるデータ構造を生成
- 意味解析
- 変数の型や文がプログラム言語の仕様に沿っているかチェック、構文木を元に中間コードを生成
- 最適化
- 処理効率の向上を目的として、より良いプログラミングコードの再編成を検討
- 目的プログラムを生成
コンパイラの最適化手法
コンパイラの行う最適化手法にはコードサイズからみた最適化と実行速度から見た最適化という2つのアプローチ
- コードサイズから見た最適化
- 生成される目的プログラムのサイズが小さくなる
- 実行速度から見た最適化
- 実行速度が速くなることで処理に要する時間が小さくなる
具体的にやること
- 関数のインライン展開
- 本来はサブルーチンとして切り分けている関数を丸ごと呼び出し位置に展開
- 関数呼び出しに要する時間を削減でき実行速度は上がるが、コードを展開する分サイズは増加
- ループ内不変式の移動
- 繰り返し処理であるループの中で値の変化がない式をループの外へと追い出す
- ループ中に行う処理の量が減るので実行速度が上がる
- コードサイズは変わらない
- ループのアンローリング
- ループ処理によって繰り返し部分をその繰り返し回数だけ展開したコードに差し替える
- その分コード量は増えるがループ判定の処理がなくなるので実行速度は上がる
- レジスタへの変数割付け
リンカの仕事
- プログラムは自分で分割したモジュールやライブラリを全てつなぎ合わせることで実行に必要な機能がそろったプログラムファイルになる
- 「つなぎ合わせる」作業をリンク(連携編集)と呼ぶ
- これがリンカ(連携編集)の仕事
- 「あらかじめリンクしておく手法」を静的リンクと呼ぶ
- 「プログラムの実行時に、共有ライブラリやシステムライブラリをロードしてリンクする手法」は動的リンクと呼ぶ
ローダの仕事
- ロードモジュールを主記憶装置に読込ませる作業をロードと呼ぶ
構造化プログラミング
構造化プログラミングはプログラムを機能単位の部品に分けて、その組み合わせによって全体を形作る考え方
制御構造として使う3つの約束
構造化プログラムでは原則的に3つの制御構造だけを使ってプログラミングを行う
- 順次構造
- 上から順に処理を実行
- 選択構造
- 何らかの条件によって分岐させいずれかの処理を実行
- 繰り返し構造
- ある条件が満たされるまで一定の処理を繰り返す
変数は入れ物として使う箱
プログラムは主記憶上に任意の箱を設けて自由に値を出し入れすることができる 変数はメモリの許す限りいくつでも使うことができる。個々の変数には名前をつけて管理
データ造構
「プログラムの中でどのようにデータを保持するか」はアルゴリズムを考える上で欠かせない検討項目。「データを配置する方法」を指してデータ構造と呼ぶ
- 配列
- メモリ上に連続した領域にデータを並べて管理する
- 配列では同じサイズのデータを連続して並べることになる
- ただし、最初に固定サイズでまとめてごっそり領域を確保してしまうためデータの挿入や削除などは不得意
- リスト
- データとデータを数珠繋ぎにして管理するのがポイント
- リストを扱うデータにはポインタと呼ばれる番号がセットになってくっついてくる
- ポインタさえ書き換えれば、いくらでもデータを繋ぎ換えることができるのでデータの追加・挿入、削除などが簡単
- ただし、リストはポインタを順位辿らなければ行けないので配列みたいに「添え字を使って個々のデータに直接アクセスする」
- 単方向リスト
- 次のデータへのポインタを持つリスト
- 双方向リスト
- 次のデータのポイントと、前のデータへのポインタを持つリスト
- 循環リスト
- 次へのデータへのポインタを持つリスト
- 最後尾データは先頭データへのポインタを持つ
- キュー
- スタック -スタックはキューの逆で最後に格納したデータから順に処理を行う、後入れ先だし方式のデータ構造
ネットワーク
LANとWAN
事業所など局地的な狭い範囲のネットワークをLAN(Local Area Network)、LAN同士をつなぐ広域ネットワークをWAN(Wide Area Network)と呼ぶ
データを運ぶ通信路の方式とWAN通信技術
- コンピュータがデータをやりとりするためには互いを結ぶ通信路が必要
- もっともシンプルな形は互いを直接1本の回線で結んでしまうこと。これを専用回線方式
- 複数のコンピュータが繋がることできるようにしたのが交換機が回線の選択を行って必要に応じた通信路が確立される方式を交換方式という
- 交換方式には2種類ある
- 回線交換方式
- 送信元から送信先にまで至る経路を交換機が繋ぎ、通信路として固定する
- 通信路に選ばれた回線は使用中のペアに占有されるので、他の端末がその回線を使うことができない
- パケット交換方式
- パケット(小包の意)という単位に分割された通信データを交換機が適切な回線へと送り出すことで通信路を形成
- コンピュータ側
- 送信データをバラバラに分割してパケットにする
- パケットにしたものを回線に送り出す
- 交換機側
- パケットを受け取り宛先を確認して適切な回線へと送る
- コンピュータ側
- 回線が使用中になるのはパケットという小さなデータが送られる短時間だけ
- しかもその間の次のパケットを交換機が蓄積してくれるので、複数の端末で回線を共有して使うことができる
- WANの構築で拠点間を接続する場合などを除いては現在のコンピュタネットワークで用いられるのは基本的には全てパケット交換方式
- パケット(小包の意)という単位に分割された通信データを交換機が適切な回線へと送り出すことで通信路を形成
- 回線交換方式
LANの接続形態(トポロジー)
LANを構築する時に各コンピュータをどのようにつなぐか。その接続形態のことをトポロジーと呼ぶ
- スター型
- ハブを中心として放射状に各コンピュータを接続する形態
- バス型
- 1本の基幹となるケーブルに各コンピュータを接続する形態
- リング型
- リング状にコンピュータを接続する形態
現在のLANはイーサネットがスタンダード
- LANの規格としては現在もっとも普及しているのはイーサネット
- IEEE(米国電気電子技術者協会)によって標準化されており、接続形態や伝送速度ごとに規格が分かれている
- 伝送速度に使われているbps(Bite per Second)という単位は1秒間ごとに送ることのできるデータ量(ビット数)を表している
イーサネットはCSMA/CD方式でネットワークを監視する
イーサネットはアクセス制御方式としてCSMA/CD方式を採用している。
- CSMA/CD方式ではネットワーク上の通信状況を監視して、他に送信を行っていう者がいない場合に限ってデータを送信する
- それでも同時に送信してしまし、通信ポケットの衝突(コリジョン)が発生した場合各々ランダムに求めた時間分待機してから再度送信する
- このように通信を行うことで1本のケーブルを複数のコンピュータで共有することができる
トークリングとトークンパッシング方式
リング型LANの代表格であるトークンリングではアクセス制御方式にトークンパッシング方式を用いる
- トークンパッシング方式
- 送信の権利を表すトークンという小さなデータがネットワーク上をバケツリレーされながら一方向で流れている
- 平常時はトークンだけでネットワークをぐるぐる流れている
- データを送信したい時はこのトークンにデータをくっつけて次へ流す
- 「自分宛じゃない」場合はそのまま次へ流し、「自分宛」の場合はデータを受け取ってから「受信した」マークをつけて再度ネットワークに流す
- マークが付加されたトークンが送信元に到着すると、送信元はトークンをフリートークンに戻してからネットワークに放流し、平常時の状態へと戻る
線がいらない無線LAN
ケーブルを必要とせず、電波などを使って無線で通信を行うLANが無線LAN
クライアントとサーバ
ネットワークにより複数のコンピュータが組み合わさって働く処理の形態にはいくつか種類がある
- 集中処理
- ホストコンピュータが集中的に処理をして他のコンピュータはそれにぶら下がる構成
- 長所
- ホストコンピュータに集中して対策を施すことで
- データの一貫性を維持・管理しやすい
- セキュリティの確保や運用管理が簡単
- ホストコンピュータに集中して対策を施すことで
- 短所
- システムの拡張が大変
- ホストコンピュータが壊れると全体が止まる
- 分散処理
- 複数のコンピュータに負荷を分散させて、それぞれで処理を行うようにした構成
- 長所
- システムの拡張が簡単
- ホストコンピュータが壊れても全体には影響しない
- 短所
- データの一貫性を維持・管理しづらい
- セキュリティの確保や運用管理が大変
昔は大型のコンピュータが処理をする「集中管理」が主流だったが、コンピュータの性能が上がったことにより分散処理ではあるが集中処理のいいところも取り込んだようなシステム形態である「クライアントサーバシステム」が出てきた
- クライアントサーバシステム 集中的に処理した方が良い資源(プリンタやハードディスク領域など)やサービス(メールやデータベースなど)を提供するサーバと、必要に応じてリクエストを投げるクライアントという2種類のコンピュータで処理を行う構成が現在の主流
プロトコルとパケット
コンピュータは色んな約束事にのっとって、ネットワークを介したデータのやり取りを行う
プロトコルとOSI基本参照モデル
- プロトコル
- ネットワークを通じてコンピュータ同士がやり取りするための約束事
- プロトコルには様々な種類があり「どんなケーブルを使って」「どんなデータ形式で」といったことが事細かに決まっている
- それらを7階層に分けたのがOSI基本参照モデル
- 基本的にはこの第1階層から第7階層までの全てを組み合わせることでコンピュータ同士のコミュニケーションが成立している
| 何階層 | 階層名 | 説明 |
|---|---|---|
| 第7階層 | アプリケーション層 | 具体的にどんなサービスを提供するのか |
| 第6階層 | プレゼンテーション層 | データはどんな形式にするか |
| 第5階層 | セッション層 | 通信の開始から終了までどう管理するか |
| 第4階層 | トランスポート層 | 通信の信頼性はどう確保するか |
| 第3階層 | ネットワーク層 | ネットワークとネットワークをどう中継するか |
| 第2階層 | データリンク層 | 同一ネットワーク内(直で繋がっている)でどう通信するか |
| 第1階層 | 物理層 | 物理的にどう繋ぐか |
なんで「パケット」に分けるのか
TCP/IPというプロトコルを使うネットワークでは通信データをパケットに分割して通信路へ流す
- パケットは通信データを小さく分割したひとかたまり
- パケットには「通信元IPアドレス」「宛先IPアドレス」「ポート番号」などがヘッダ情報として付加されている
- 分割して流す理由は通信路上を流せるデータ量は有限だから
ネットワークの伝送速度
- 実行速度
- 一般的な使用法で実際に出る速度のこと
- 伝送効率
- 理論値に対して実際に出る速度の割合
ネットワークを構成する装置
ネットワークの世界で働く装置にはルータやハブ、ブリッジ、リピータなどがある
LANの装置とOSI基本参照モデルの関係
ネットワークで用いる各装置は「どの層に属するか」「なにを中継するのか」を知ることでより理解しやすくなる
| 何階層 | 階層名 | 装置 |
|---|---|---|
| 第7階層 | アプリケーション層 | ゲートウェイ |
| 第6階層 | プレゼンテーション層 | ゲートウェイ |
| 第5階層 | セッション層 | ゲートウェイ |
| 第4階層 | トランスポート層 | ゲートウェイ |
| 第3階層 | ネットワーク層 | ルータ |
| 第2階層 | データリンク層 | ブリッジ |
| 第1階層 | 物理層 | LANケーブル、NIC、リピータ |
- ゲートウェイ
- ルータ
- ブリッジ
- データリンク(第2層)に位置する装置
- パケットのMACアドレス情報を使ってネットワーク内のセグメント間を中継する
- LANケーブル、NIC、リピータ
- 物理層(第一層)に位置していて電気的な信号を送ったり受けたり増幅したりする
NIC(Network Interface Card)
コンピュータをネットワークに接続するための拡張カード。LANボードとも呼ばれる
- NICの役割はデータを電気信号に変換してケーブル上に流すこと。そして受け取ること
- 要するにコンピュータがネットワークでやり取りしようと思ったら欠かすことのできない部品がNIC
- NICをはじめとするネットワーク機器には製造段階でMACアドレスという番号が割り振られている
- イーサネットではこのMACアドレスを使って各機器を選別する
リピータ
- リピータは物理層(第一層)の中継機能を提供する装置
- ケーブルを流れる電気信号を増幅して、LANの総延長距離を伸ばす
- パケットの中身を解さず、ただ電気信号を増幅するだけなので不要なパケットも中継する
- ネットワークに流したパケットは宛先が誰かに依らずにとにかく全員にわたされる。この「無条件にデータが流される範囲(論理的に1本のケーブルでつながっている範囲)」をセグメントと呼ぶ
ブリッジ
- ブリッジはデータリンク層(第2層)の中継機能を提供する装置
- セグメント間の中継役として流れてきたパケットのMACアドレス情報を確認、必要であれば他方のセグメントとパケットを流す
- ブリッジは流れてきたパケットを監視することで最初に「それぞれのセグメントに属するMACアドレスの一覧」を記憶する
- 以降はその一覧に従ってセグメント間を橋渡しする必要があるパケットだけ中継を行う
ハブ
- ハブはLANケーブルの接続口(ポート)を複数持つ集線装置
ルータ
ルータはネットワーク層(第3層)の中継機能を提供する装置。異なるネットワーク(LAN)同士の中継役として、流れてきたパケットのIPアドレス情報を確認した後に最適な経路へとパケットを転送
- ルータの役割はそれぞれの地域(LAN)を担当する郵便屋さんみたいなもの
- 自分の担当地域外宛のパケットが流れてきたらその地域を担当するルータに配送を依頼する
- ブリッジが行う転送はあくまでMACアドレスが確認できる範囲のみ有効であり外のネットワーク宛のパケットを中継することはできない
- ルータはパケットに書かれた宛先IPアドレスを確認し最適な転送先を選ぶ。これを経路選択(ルーティング)と呼ぶ
- IPアドレスは「どのネットワークに属する何番のコンピュータか」という内容を示す情報
ゲートウェイ
- ゲートウェイはトランスポート層(第4層)以上が異なるネットワーク間でプロトコル変換による中継機能を提供する装置
- ネットワーク双方で使っているプロトコルの差異をこの装置が変換、吸収することでお互いの接続を可能にしている
- 異なるプロトコルの間に位置して相互に変換を行うのがゲートウェイの役割
データの誤り制御
データの誤りとはビットの内容が「0→1」「1→0」とノイズやひずみによって異なる値に化けてしまうこと
- ケーブル上を流れるのはあくまで単なる電気信号のみ
- この信号の波形を「この範囲の波形は0」「この範囲の波形は1」と値に置き換えることでビットの内容をやり取りしている
- データの誤りを100%確実に防ぐことはない
- そこでパリティチェックやCRC(巡回冗長検査:Cyclic Redundancy Check) などの手法を用いて誤りを検出したり訂正したりする
パリティチェック
パリティチェックでは送信するビット列に対してパリティビットと呼ばれる検査用のビットを付加することでデータの誤りを検出する
ただしバリティチェックで可能なのは「1ビットの誤り」を検出するだけしかできない
水平垂直パリティチェック
パリティビットは「どの方向に付加するか」によって垂直パリティと水平パリティに分かれる

CRC(巡回冗長検査)
CRC(Cyclic Redundancy Check)はビット列を特定の式でわりその余りをチェック用のデータとして付加する方法
- ビット数を特定の式でわる
- 余りをくっつけて、1の特定の式で割ったら余りが出ない状態にする
- 余りが出たらビットが狂ったことがわかる
TCP/IPを使ったネットワーク
TCPとIPという2つのプロトコルの組み合わせがインターネットにおけるデファクトスタンダード
- IPは「複数のネットワークを繋いで、その上をパケットが流れる仕組み」を規定
- TCPはそのネットワーク上で「正しくデータが送られたことを保証する仕組み」を定めたもの
- 両者が組みあわさることで「複数のネットワークを渡り歩きながらパケットを正しく相手に送り届けることができる」
- こうしたインターネットの技術をそのまま企業内LANなどに転用したネットワークのことをイントラネットと呼ぶ
- 下の表のトランスポート層がTCP、ネットワーク層がIP
| 何階層 | 階層名 | 説明 |
|---|---|---|
| 第7階層 | アプリケーション層 | 具体的にどんなサービスを提供するのか |
| 第6階層 | プレゼンテーション層 | データはどんな形式にするか |
| 第5階層 | セッション層 | 通信の開始から終了までどう管理するか |
| 第4階層 | トランスポート層 | 通信の信頼性はどう確保するか |
| 第3階層 | ネットワーク層 | ネットワークとネットワークをどう中継するか |
| 第2階層 | データリンク層 | 同一ネットワーク内(直で繋がっている)でどう通信するか |
| 第1階層 | 物理層 | 物理的にどう繋ぐか |
TCP/IPの中核プロトコル
ネットワーク層のIPが網としての経路機能を担当し、その上のTCPやUDPが「ではその経路で小包(パケット)をどのように運ぶのか」という約束事を担当
IP(Internet Protocol)
- 経路制御を行い、ネットワークからネットワークへとパケットを運んで相手に送り届ける
- コネクションレス型の通信(事前に送信相手と接続確認を取ることなく一方的にパケットを送りつける)であるため通信品質の保証については上位層に任す
TCP(Transmission Control Protocol)
- 3ウェイハンドシェイクという手順によって通信相手とコネクションを確立し、データを送受信するコネクション型の通信プロトコル
- パケットの手順や送信エラー時の再送などを制御して、送受信するデータの信頼性を担保

- UDP(User Datagram Protocol)
IPアドレスはネットワークの住所なり
- IPで構成されるネットワークでは繋がれているコンピュータやネットワーク機器はIPアドレスという番号により管理される
- 個々のコンピュータを識別するために使うものだから重複があってはいけない
- IPアドレスは32ビットの数値であらわされる
グローバルIPアドレスとプライベートIPアドレス
IPアドレスにはグローバルIPアドレスとプライベートIPアドレスという2種類がある
-
- グローバルIPアドレスはインターネットの世界で使用するIPアドレス
- 世界中で一意であることが保証されていないといけない
- 地域ごとのNIC(Network Information Center)と呼ばれる民間の非営利機関によって管理
プライベートIPアドレス
- 企業内などLANの中で使えるIPアドレス
- LAN内で重複がなければシステム管理者が自由に割り当てて使うことができる
グローバルIPアドレスとプライベートIPアドレスの関係は電話の外線と内線の関係によく似ている
IPアドレスは「ネットワーク部」と「ホスト部」で出来ている
IPアドレスの内容はネットワークごとに分かれるネットワークアドレス部と、そのネットワーク内でコンピュータを識別するためのホストアドレス部とに分かれている。つまり、「住所と名前」で構成されている
↓ここまではネットワークアドレス 192.168.1.3 ↑ホストアドレス
IPアドレスのクラス
- IPアドレスは使用するネットワークの規模によってクラスA、クラスB、クラスCと3つのクラスに分かれている
- それぞれ「32ビット中の何ビットをネットワークアドレス部に割り振るか」が規定されている
- ホストアドレス部が「全て0はネットワークアドレス(ネットワーク自体を表す)」「全て1はブロードキャストアドレス(ネットワーク内全てのアドレス)」
10進表記例 255.255.255.0
2進表記例. 11111111.11111111.11111111.00000000
ブロードキャスト
ブロードキャスト
ユニキャスト
- ブロードキャストの逆の言葉として特定の1台のみに送信すること
- 複数ではあるが不特定多数ではなく決められて範囲内の複数ホストに送信する場合はマルチキャストという
サブネットマスク
- 「ホスト数はいらないから、事業部ごとにネットワークを分けたい」という場合にサブネットマスクを用いてネットワークを分割する
- 分割するメリット
- ひとつのネットワークに大量のホストをまとめると通信トラフィックが多くなりすぎて通信効率が下がる
- ブロードキャストだとネットワークの全ホスト宛に送信するので最悪
- ひとつのネットワークに大量のホストをまとめると通信トラフィックが多くなりすぎて通信効率が下がる
- 分割するメリット
- 2ビットを使って分割したネットワークが表現できる
10進表記例 255.255.255.0
2進表記例. 11111111.11111111.11111111.00000000
↑↑サブネット
TCP/IPアドレスとパケットヘッダ
 7key.jp/nw/technology/osi/osi.html
7key.jp/nw/technology/osi/osi.html
MACアドレスとIPアドレスの変換
- MACアドレスの管理は各端末に任されているが「送信先(もしくは中継先)のIPアドレスはわかるが、MACアドレスはわからない」ということが起こる
- この時に用いるプロトコルがARP(Address Resolution Protocol)
- その逆にMACアドレスからIPアドレスを取得するまめに用いるのがRARP(Reverse Address Resolution Protocol)
DHCPは自動設定する仕組み
LANにつなぐコンピュータの台数が増えてくると、1台ずつに重複しないIPアドレスを割り当てることが思いの外困難となる
NATとIPマスカレード
- LANの中ではプライベートIPアドレスを使うのが一般的だが外のネットワークとやりとりするためにはグローバルIPアドレスが必要
ルータはLAN側とWAN側の2つのIPアドレスを持っている
プライベートIPアドレスしか持たない各コンピュータはどうやって外のコンピュータとやり取りするのか
- NATやIPマスカレード(NAPTともいう)といったアドレス変換技術を使う
- NAT
- グローバルIPアドレスとプライベートIPアドレスとを1対1で結びつけて、相互に変換を行う
- 同時にインターネット接続できるのはグローバルIPアドレスの個数分だけ
- IPマスカレード
- グローバルIPアドレスに複数のプライベートIPアドレスを結びつけて1対複数の変換を行う
- IPアドレスの変換時にポート番号も合わせて書き換えるようにすることで1つのグローバルIPアドレスでも複数のコンピュータが同時にインターネット接続することができる(ポート番号とIPアドレスを対応させておく)
- NAT
- NATやIPマスカレード(NAPTともいう)といったアドレス変換技術を使う
ドメイン名とDNS
ネットワークを診断するプロトコル
- TCP/IPのパケット転送において発生した各種エラー情報を報告するために用いられるプロトコルがICMP(Internet Control Message Protocol)
- 通信エラー発生時にはその発生場所からパケットの送信元に対してICMPによってエラー情報が通知される
- これにより発生した障害内容を知ることができる
- ICMPを用いたネットワーク検査コマンドとして有名なのが次の2つ
- ping
- 指定コンピュータまでパケットが届くかを試すことでネットワークの疎通が確認できる
- traceroute
- 指定コンピュータに到達するまでの間、どのような経路を辿っているか調査できる
- ping
ネットワークを管理するプロトコル
ネットワークを構成するルータやスイッチなど、様々な機器の状態や設定を管理するために用いられるプロトコルがSNMP(Simple Network Management Protocol)
ネットワーク上のサービス
ネットワーク上で動くサービスにはそれぞれに対応したプロトコルが用意されている
代表的なサービスたち
ネットワーク上のサービスはそのプロトコルを処理するサーバによって提供されている
| プロトコル名 | 説明 | ポート番号 |
|---|---|---|
| HTTP(HyperText Transfer Protocol) | Webページの転送に利用するプロトコル。Webブラウザを使ってHTMLで記述文書を受信する時などに使用 | 80 |
| FTP(File Transfer Protocol) | ファイル転送サービスに利用するプロトコル。インターネット上のサーバにファイルをアップロードしたり、サーバからファイルをダウンロードしたりするのに使う | 制御用:20 転送用:21 |
| Talnet | 他のコンピュータにログインして遠隔操作を行う際に使うプロトコル | 23 |
| SMTP(Simple Mail Transfer Protocol) | 電子メールの配送部分を担当するプロトコル。メール送信時や、メールサーバ間での送受信時に使用 | 25 |
| POP(Post Office Protocol) | 電子メールの受信部分を担当するプロトコル。メールサーバ上にあるメールボックスから受信したメールを取り出すために使う | 110 |
| NTP(Network Time Protocol) | コンピュータの時刻合わせを行うプロトコル | 123 |
サービスはポート番号で識別する
- ネットワーク上で動くサービスたちは個々に「それ専用のサーバマシンを用意しなきゃいけない」というわけではない
- サーバというのは「プロトコルを処理してサービスを提供するためのプログラム」が動くことでサーバになっているわけで一つのコンピュータが様々なサーバを兼任することは当たり前にある
- IPアドレスだけだとパケットの宛先となるコンピュータは識別出来てもそれが「どのサーバプログラムに宛てたものか」までは特定できない
- そこでプログラムの側では0~65536までの範囲で自分専用の接続口のを設けて待つようになっている
- この接続口をポート番号と呼ぶ
WWW(World Wide Web)
- WWWはインターネットで標準的に使われているドキュメントシステム
- 散在するドキュメント同士が相互に繋がりを持つのが特徴
- このサービスではWebブラウザを使って世界中に散在するWebサーバから文字や画像、音声などの様々な情報を得ることができる
Webサーバに「くれ」と言って表示する
WWWのサービスにはWebサーバとWebブラウザが欠かせないがそのやりとりはすごく単純
Webサーバ
- 公開用のファイルを管理
サーバの仕事というのは基本的に「くれ」と言われたファイルを渡すだけ
- なにかデータを整形したり特別な処理を加えたりはしない
- WebブラウザとWebサーバのやり取りに使われているのプロトコルがHTTP
WebページはHTMLで記述する
WebページHTML(Hyper Text Markup Language)という言語で記述されている
URLはファイルの場所を示すパス
Web上で取得したいファイルの場所を指し示すにはURL(Uniform Resource Locator)という表記方法を用いる
電子メール
- 電子メールではネットワーク上のメールサーバをポスト兼私書箱のように見立ててテキストや各種ファイルをやり取りする
メールアドレスは名前@住所なり
ユーザ名@ドメイン名
ryohei.udagawa@onecareer.jp
電子メールを送信するプロトコル(SMTP)
電子メールを実際の郵便に置き換えると
- ポストに入れる
- 郵便屋さんが運ぶ
- 郵便受けに届く
- 郵便受けから取り出す
1~3がSMTPの役割
電子メールを受信するプロトコル(POP)
電子メールを受信するにはPOPというプロトコルを使用する
メタプログラミング
1章
メタプログラミングとは、言語要素を実行時に操作するコードを記述することである
2章 オブジェクトモデル
オープンクラス
Rubyは既存のクラスを再オープンして、その場で修正できる。この技法をオープンクラスという。
class string
def to_alphanumeric
gsub(/[^\w\s], '')
end
end
オープンクラスのダークサイド
何も考えずにクラスにコードを追加すると、元々あるメソッドを上書きしてしまい思わぬバグに繋がってしまう。こうしたクラスへの安易なパッチをモンキーパッチという。
オブジェクトモデルの内部
インスタンス変数
- Rubyのオブジェクトのクラスとインスタンス変数には何の繋がりもない
- 同じクラスのオブジェクトであってもインスタンス変数の数が異なることがある
- インスタンス変数の名前と値はハッシュのキーとバリューのようなもの
メソッド
- インスタンス変数の他にオブジェクトはメソッドを持っている
- ほとんどのオブジェクトはObjectクラスから多くのメソッドを継承している
- Objを中身を見ると、メソッドがなくインスタンス変数とクラスへの参照があるだけ(全てのオブジェクトはクラスに属しているから。オブジェクト指向的に言えば、全てのオブジェクトはクラスのインスタンスだから。)
クラスの真相
- Rubyのオブジェクトモデルを学ぶときに最も重要なのは「クラスはオブジェクト」ということ
- クラスはオブジェクトなので、オブジェクトに当てはまるものはクラスに当てはまる
- オブジェクトと同じように、クラスにもクラスがある。
- クラスのメソッドはClassクラスのインスタンスメソッドである。
モジュール
- ClassクラスのスーパークラスはModule
- 全てのクラスはモジュールである。正確にいうとクラスはオブジェクトの生成やクラスを継承するための3つのインスタンスメソッド(new, allocate, superclass)を追加したモジュール
- クラスとモジュールは密接に結びついているため、Rubyは同じ役割を担う「モノ」と見なすことができる。
- モジュールとクラスを分ける理由はどちらかを選択することによりコードが明確になるから
定数
- 大文字で始まる参照は、クラス名やモジュール名も含めて全て定数。
- プログラミにある全ての定数は、ファイルシステムのようにツリー状に配置されており、モジュールがディレクトリで、定数がファイル
- ファイルシステムと同じようにディレクトリが違えば同じ名前のファイルを複数持つことができる
- 定数のパスは
::で区切る
オブジェクトとクラスのまとめ
- オブジェクトとはインスタンス変数の集まりにクラスへのリンクがついたもの
- オブジェクトのメソッドはオブジェクトではなくオブジェクトのクラスに住んでいてクラスのインスタンスメソッドと呼ばれる
- ClassクラスはModuleクラスのサブクラスであり、クラスもモジュールである
- Classクラスにはインスタンスメソッドがある。通常のオブジェクトと同じようにクラスもnewなどのメソッドを持っている
メソッドを呼び出すときに何が起きている?
メソッドを呼び出すときRubyは以下の2つを行う - メソッドを探す(メソッド探索) - メソッドを実行する(selfと呼ばれるものが必要)
メソッド探索
- メソッドを呼び出すときにはRubyはオブジェクトのクラスを探索してメソッドを発見している
- レシーバーは呼び出すメソッドが属するオブジェクトのこと
- 継承チェーンはあるクラスの継承先をBasicObjectまで続けた道筋
- メソッド探索を一言でまとめると「Rubyがレシーバのクラスに入り、メソッドを見つけるまで継承チェーンを上がること」
モジュールとメソッド探索
- 継承チェーンにはスーパクラスに向かって進んでいくが、継承チェーンにはモジュールも含まれる
- モジュールをクラスにインクルードするとRubyはモジュールを継承チェーンに挿入し、それはインクルードするクラスの真上に入る
- 同じモジュールを2回挿入した時は2回目の挿入を無視する
- Kernelモジュールは全てのクラスでインクルードされており、ppやprintなどのメソッドをKernelモジュールで定義している
メソッドの実行
selfキーワード
- Rubyのコードはオブジェクト(カレントオブジェクト)の内部で実行される。カレントオブジェクトはselfと呼ばれる
- selfの役割を担えるオブジェクトは同時に複数は存在しない。
- メソッドを呼び出す時はメソッドのレシーバがselfになる。その時点から全てのインスタンス変数はselfのインスタンス変数になり、レシーバを明示しないメソッド呼び出しは全てselfに対する呼び出しになる。レシーバを明示しないメソッド呼び出しは全てselfに対する呼ぶ出しになる。
クラス定義とself
- クラスやモジュールの定義の内側(メソッドの外側)ではselfの役割はクラスやモジュールそのものになる
3章 メソッド
動的メソッド
- 通常は
.to_sのようにメソッドを呼び出すが、同じことをsendメソッドを使ってできる。 sendメソッドを使用することで呼び出すメソッドを動的にできる
メソッドを動的に定義する
- define_methodを使用すれば、メソッドをその場で定義できる。それにはメソッド名とブロックを渡す必要があり、ブロックがメソッドの本体になる。
- defキーワードではなく、Module#define_methodを使う理由はdefine_methodを使用すれば実行時にメソッド名を決定できるから。
method_missingを使う
- method_missingはクラス、そのクラスのスーパークラスにメソッドがないとき呼び出される
- これを利用して同じようなメソッドを何回も書くのではなくmethod_missingをオーバーライドしフックとすることでまとめることができる
4章 ブロック
ブロックの基本
- ブロックは
{}やdo...endキーワードで定義できる - ブロックを定義できるのはメソッドを呼び出すときだけ
computers.each do |computer| ~ end
ブロックはクロージャ
- ブロックはどこにでも存在できるコードではなく、ブロックのコード単体では実行できない
- ブロックのコードを実行するにはローカル変数、インスタンス変数、selfといった環境が必要。これらはオブジェクトに紐づられた名前のことで束縛と呼ばれる
- つまり、ブロックとはコードと束縛をまとめ実行の準備をするもの
- ブロックからは呼び出されるメソッドで定義された変数は見ることができない。これらの特性があるためブロックはクロージャであるというコンピュータ科学者もいる
スコープ
- ある変数や関数が特定の名前で参照される範囲のこと
- プログラムがスコープを変えると新しい束縛と置き換えられる
スコープゲート
- プログラムがスコープを切り替えて新しいスコープをオープンする場所は3つある
- クラス定義
- モジュール定義
- メソッド
- これらの3つの境界線はclass, module, defといったキーワードが印付けられており、この3つのキーワードはスコープゲートとして振る舞う
スコープのフラット化
- スコープゲートをメソッド呼び出しに置き換えると、他のスコープの変数が見えるようになる
- これを入れ子構造のレキシカルスコープと呼んだり、「スコープのフラット化」と読んだりもする。後者は2つのスコープを一緒の場所に押し込めて、変数を共有するという意味。
クロージャのまとめ
- Rubyのスコープには多くの束縛がある。スコープはclass, module, defといったスコープゲートで区切られる
- スコープゲートを飛び越えて束縛にこっそり潜り込みたい時はブロックを使う。ブロックとはクロージャである
- classはClass.newと、moduleはModule.newと, defはModule.define_mothodと置き換えることが可能。これをフラットスコープと呼ぶ
- 同じフラットスコープに複数のメソッドを定義してスコープゲートを守ってやれば束縛を共有でき、これを共有スコープと呼ぶ
instance_eval
instance_evalに渡したブロックはレシーバをselfにしてから評価されるので、レシーバのprivataメソッドや@vなどのインスタンス変数にもアクセスできる
class Myclass
def initialize
@v = 1
end
obj = MyClass.new
obj.instance_eval do
self # => <MyClass:>
@v # => 1
end
クリーンルーム
- ブロックを評価するためだけにオブジェクトを生成することもある。
- クリーンルームとはブロックを評価する環境のこと。
呼び出し可能オブジェクト
- ブロックの使用は2つのプロセスに分けられる
- まずはコードを保管すること
- それからブロックを(yieldを使用して)呼び出して実行する
- 「コードを保管しておいて、後で呼び出す」方式はブロックだけに限らず、Rubyでコードを」保管できるところは少なくても3つある
- Procのなか。これはブロックがオブジェクトになったもの
- lambdaのなか。これはProcの変形
- メソッドのなか。
Procオブジェクト
- Rubyではほぼ全てがオブジェクトだが、ブロックは違う
- Procはブロックをオブジェクトにしたもの。Procを生成するには、Proc.newをブロックに渡す
- オブジェクトになったブロックをあとで評価するにはProc#callを呼び出す
ques = Proc.new { |x| x + 1 }
qies.call(2) # => 3
「Proc」対「lambda」
- Procとlambdaの違いは2つある
- returnキーワードに関すること
- lambdaのreturnは単にlambdaから戻るだけ
- Procの場合はProcが定義されたスコープから戻る
- 引数チェックに関すること(引数の数が違う時の挙動の違い)
- lambdaは引数の数が違う時「ArgumentError」を出力する
- Procは引数列を期待に合わせてくれる
- returnキーワードに関すること
Methodオブジェクト
- メソッド自体もMethodオブジェクト
呼び出し可能オブジェクトのまとめ
- ブロック(オブジェクトではないが呼び出し可能):定義されたスコープで評価
- Proc:Procクラスのオブジェクト。ブロックのように定義されたスコープで評価
- lambda:これもProcクラスのオブジェクトだが、通常のProcとは少し違う。ブロックやProcと同じくクロージャであり、定義されたスコープで評価される
- メソッド:オブジェクトに束縛され、オブジェクトのスコープで評価される。オブジェクトのスコープから引き離し、他のオブジェクトに束縛することも可能
クラス定義 5章
- クラスは高機能なモジュールである
クラス定義の中身
- クラス定義のことはメソッドを定義する場所だと思っているかもしれない。実際にはクラス定義にはあらゆるコードを書くことができる。
class MyClass puts 'Hello' end
=> Hello
- クラス(やモジュール)定義の中ではクラスがカレントオブジェクトselfになる
- クラスとモジュールは単なるオブジェクトであり、クラスもselfになることが可能
カレントクラス
- Rubyのプログラムは常にカレントオブジェクトselfを持っている。それと同様に常にカレントクラス(あるいはカレントモジュールを持っている)
- メソッドを定義するとそれはカレントクラスのインスタンスメソッドになる
- カレントクラスを参照するキーワードはないが、コードを見ればわかる
- プログラムのトップレベルではカレントクラスはmainのクラスのObjectになる
- classキーワードをクラスをオープンにすると、そのクラスがカレントクラスになる
- メソッドの中ではカレントオブジェクトのクラスがカレントクラスになる
カレントクラスのまとめ
- Rubyのインタプリタは常にカレントクラスの参照を追跡している。defで定義された全てのメソッドはカレントクラスのインスタンスメソッドになる
- クラス定義の中では、カレントオブジェクトselfとカレントクラス(定義しているクラス)は同じである
- クラスへの参照を持っていれば、クラスはClass_evalでオープンできる
クラスインスタンス変数
class MyClass @my_var = 1 def self.read; @my_var; end def write; @my_var = 2; end def read; @my_var; end end obj = MyClass.new obj.read #=> nil obj.read obj.write obj.read #=> 2 My.Class.read # =>1
- 上の@my_varはそれぞれ異なるスコープで定義されており、別々のオブジェクトに属している
- クラスが単なるオブジェクトであることと、プログラムの中のselfを追跡することを思い出す必要がある
- 1つ目の@my_varはobjがselfとなる場所に定義されており、objオブジェクトのインスタンス変数
- 2つ目の@my_varはMyClassがselfとなる場所に定義されており、これはMyClassというオブジェクトのインスタンス変数。クラス変数とも呼ばれる
特異メソッド
- Rubyでは特定のオブジェクトにメソッドを追加できる。単一のオブジェクトに特化したメソッドのことを特異メソッドと呼ぶ。
class Movie
def i_method
p 'instance method'
end
end
obj1 = Movie.new
obj2 = Movie.new
def obj1.s_method
p 'singlton method'
end
obj1.i_method #=> 'instance method'
obj2.i_method #=> 'instance method'
obj1.s_method #=> 'singlton method'
obj2.s_method #=> undefined method `s_method' for #<Movie:0x00007fc2fc842c38> (NoMethodError)
クラスメソッドの真実
- クラスは単なるオブジェクトであり、クラス名は単なる定数
- クラスメソッドはクラスの特異メソッド
特異クラス
- 通常のクラスとは別にオブジェクトは裏に特別なクラスを持っている
- それがオブジェクトの特異クラスと呼ばれるもの(メタクラスやシングルトンクラス)
- 特異クラス(シングルトンクラス)はインスタンスをひとつしかもてない
- 継承ができない
- 特異クラスはオブジェクトの特異メソッドが住んでいる場所だ
- 特異メソッドを定義するとそのオブジェクトの特異クラスが作成されるため、特定のオブジェクトでしかメソッドが実行できない
大統一理論
- オブジェクトは1種類しかない。それが通常のオブジェクトかモジュールになる
- モジュールは1種類しかない。それが通常のモジュール、クラス、特異クラスのいずれかである
- 全てのオブジェクトは「本物クラス」を持っている。それが通常のクラスか特異クラスである
- 全てのクラスは(BasicObjectを除いて)一つの祖先(スーパークラスかモジュール)を持っている。つまり、あらゆるクラスがBasicObjectに向かって1本の継承チェーンを持っている
- オブジェクトの特異クラスのスーパークラスは、オブジェクトのクラスである。クラスの特異クラスのスーパークラスはクラスのスーパークラスの特異クラスである
- メソッドを呼び出す時はRubyはレシーバの本物のクラスに向かって「右へ」進み、継承チェーンを「上へ」進む。
メソッドラッパー
docker
Dockerとは何か
- コンテナ型仮想環境を作成、実行、管理するためのプラットフォーム
- Dockerのソフトウェアを使って素早くコンテナを起動し、様々なアプリケーションを実行することができる
- 異なる環境で簡単に同じ仮想環境を再現できる
- Dockerのソフトウェア自体はGo言語で書かれている
用語
Dockerイメージ
Dockerコンテナを作成するための雛形となるもの Dockerイメージはアプリケーション、ライブラリ、設定ファイルなどのアプリケーション実行に必要なものを一式をまとめたもの 出来上がったアプリケーションをDockerイメージとして保存して、別のサーバーに持っていくことで同じ環境を別のサーバー上で再現が可能
Dockerコンテナ
Dockerイメージを元に作成されるコンテナ型仮想環境のことをDockerコンテナ、または単にコンテナと呼ぶ イメージからコンテナを作成することで何度でも簡単に同じコンテナ(仮想環境)を作成することができる コンテナを起動することで予めイメージにセットアップしたアプリケーションの機能を提供することができる
Docker Hub
Dockerイメージを保存するための機能などを提供しているサービス ベンダーや他のユーザーが作ったイメージも公開されており、公開されているイメージをダウンロードすることでさまざまなコンテナを起動することができる
ホストOS
仮想化において、仮想サーバーを起動させる側のOSのことをホストOSをいう ホストOS上に仮想化のソフトウェアをインストールすることで、仮想マシンを作成して複数の仮想環境を起動することが可能
ゲストOS
仮想化において、ホスト上に作成された仮想マシン上で動作するOSのことをゲストOSと呼ぶ
Virtual Machine
仮想環境のことをVirtual Machineを略してVMと呼ぶ。一般的にはホスト型仮想化の仮想マシンのことを指す
ホスト型仮想化
ホストOSにハイパーバイザーと呼ばれる仮想化の機能を用意して行う仮想化のことをホスト型仮想化という ハイパーバイザーの機能を提供するソフトウェアとして、Virtual Boxなどがある。 ホストOSに依存せずに仮想マシンに好きなOSをインストールできる点や、仮想マシン間の分離レベルが高い点などがコンテナ仮想化と異なる
コンテナ型仮想化
Dockerといったコンテナ仮想化を行うソフトウェアを用いて行う仮想化をコンテン型仮想化という Dockerの場合はDockerエンジンによってコンテナの作成、削除などの管理が行われる ホスト型とは異なり、ゲストOSというものはなく、ホストOSのカーネルを共有してアプリケーションが実行される
ハイパーバイザー
ホスト型仮想化の仮想マシンを管理するための機能を提供するものがハイパーバイザー。 ホストOSとゲストOSの間を仲介する形でハイパーバイザーが機能する
Dockerエンジン
Dockerにおいてコンテナ型仮想化を実現するためのコアとなる機能をもった部分がDockerエンジン Dockerエンジンによってコンテナ作成などの機能が提供される ここにコマンドで指示することでコンテナが立ち上がったりする
オーバーヘッド
コンピューターで何らかの処理を行う際に、その処理を行うために余計に費やされるシステムへかかる負荷や処理時間などのこと
ミドルウェア
コンピュータの基本的な制御を行うオペレーティングシステムと、各業務処理を行うアプリケーションソフトウェアとの中間に入るソフトウェアのことをミドルウェアと呼ぶ WebアプリケーションではデータベースサーバーやWebサーバー、アプリケーションサーバーへの機能を提供するミドルウェアなどが頻繁に使用されている
カーネル
OSのコアとなる部分をカーネルという。 ハードディスクやメモリーなどコンピューターリソースの管理や、プログラムの実行プロセスへのリソースの割り当てなどを行う
パッケージ
特定の機能を提供するために、必要なプログラムをまとめたものをパッケージと呼ぶ Linuxサーバーなどでは、公開されている様々なパッケージをインストールすることで、サーバーとしての機能を追加することができる
ホスト型仮想化とコンテナ型仮想化の違い
仮想化のオーバーヘッド
ホスト型仮想化 - リソース(CPUやメモリの使用率など)の面でオーバーヘッドが多く、起動や停止に時間がかかる コンテナ型仮想化 - コンテナはアプリケーション実行に必要なものだけを含み、ホストOSのカーネルを使用するため、動作が早くリソースの使用率も少なくて済む。
アプリケーション実行の再現性
ホスト型仮想化 - 仮想マシンの環境の違いによりアプリケーションが動作しなくことが稀に発生する
コンテナ型仮想化 - 特定のアプリケーションを動作させるために必要なものはDockerイメージにまとまっており、同じDockerイメージからコンテナを起動する限り、環境が変わっても同様に動作する
OSの自由度
ホスト型仮想化 - 仮想マシン上で任意のOSを動作させることができる コンテナ型仮想化 - コンテナはホストOSのカーネルを使用して動作するので、WindowOS上で直接Linuxコンテナを動作させることができない - またLinuxOS上で直接Windowsコンテナも動作させることもできない
分離レベル
ホスト型仮想化 - ハードウェアレベルtで仮想化されており、ホストOSや仮想マシン間の分離レベルが高く、それぞれが影響を受けにくい - OSの機能を使用した仮想化は、従来の仮想化に比べて分離レベルは低い
用語解説
Dockerデーモン
Dockerの常駐型プログラミングでDockerコンテナの作成やDockerイメージの作成などDockerに対する操作はこのDockerデーモンが受け取り、実際の処理を行う Dockerデーモンが起動していないとDockerに対する操作を受け取れないためエラーになる そのため、もし停止している場合には事前に起動しておく必要がある
Dockerクライアント
Dockerの利用者がDockerに指示を出すためのクライアントソフト。 一般的にはdockerコマンドを用いてDockerに指示を出す
PCでのDocker実行環境
次の順で実行される 1. Dockerクライアント(Dockerコマンド) 2. Dockerデーモンが受けとる 3. コンテナに指示を出す ※DockerデーモンはLinuxの仮想マシン(軽量)の中で行われる。 ← インストールしたdockerが自動でやってくれる
用語解説
バインドマウント
DockerにおいてOS(Dockerデーモンが動作しているOS)上のファイルをコンテナに共有する機能をバインドマウントという。 ソフトウェアの開発時など、PCでソースコードを変更してDockerコンテナ上で実行したい場合などにソースコードのあるフォルダをコンテナにバインドマウントしてプログラムを実行するといった使い方が良くされる
Kubernetes
コンテナのオーケストレーションツール。 オーケストレーションツールとは主に複数のコンテナを効率よく管理するための機能が備わったツールのこと。 様々なコンテナが多数動作する環境において、使用するイメージ、コンテナへのCPUやメモリの割り当て、コンテナ停止時の復旧処理、パスワードなどの秘匿情報の管理、ストレージの割り当て、コンテナの稼働状況の監視等様々なことを考慮する必要があるため、管理が難しくなる Kubernetesはこういったコンテナ管理の機能を持ったソフトウェアであり、コンテナを管理するための設定ファイルを書くことで様々なコンテナ管理の機能を利用することができる
hello-worldの実行と動作の解説
docker run コマンドの実行時の動作
docker run コマンドは複数のコマンドを合わせたもの - docker pull: イメージの取得 - docker create: コンテナの作成 - docker start: コンテナの起動
用語解説
レジストリ
Dockerの文脈ではリポジトリを管理する場所のことをレジストリをいう。 リポジトリの作成など、リポジトリの管理機能を提供するサービスをレジストリサービスという。 レジストリの機能を提供するサービスとしては、Docker Hubなどがある。レジストリにDockerイメージを保存することで異なる環境間にイメージを移送することが可能
タグ
イメージに付けることができるラベル名のことをタグという。バージョンの管理に使う
ビルド
Dockerの文脈において、DockerfileからDockerイメージを作成することをビルドという
Docker Hubとは
- Dockerイメージのレジストリサービス
- Dockerイメージの公開、検索、ダウンロードをすることができる
用語解説
ファイルシステム
コンピューター上でファイルを管理するための機能のことをファイルシステムという。 通常ファイルシステムの機能はOSに備わっている
ストレージドライバ
ハードディスクなどのストレージにデータを書き込むための機能を持ったソフトウェアのこと。 ストレージドライバによってデータの書き込み形式や管理方法は異なる
AUFS
Dockerで使用できるストレージドライバの一種。 Dockerの説明においてはファイルシステムの一種として解説されているものもある Dockerイメージをどのようにストレージに保持するのかを司るソフトウェアとしてAUFSという選択肢があるという風に理解する
Dockerイメージとは
- コンテナに必要なファイルをまとめたファイルシステム
- AUFSなどの特殊なファイルシステムが使用されている
- イメージ上のデータはレイヤで構成され読み取り専用
- コンテナで立ち上げる際にイメージから読み取ったものは読み取り専用であり、直接編集できない。読み取り専用の上に読み書き可能なコンテナレイヤーが積み上げられ、そこから下のレイヤーのファイルを削除することができるが、元々のレイヤーは消えない。イメージのファイルを小さくすることがdockerでは大切なので削除を検討する場合、イメージから削除する方法を考えた方が良い
- イメージはできるだけ小さくしたほうが良い。 ベースイメージ(CentOSなど)が共通している場合は共通部分は同じイメージを使用することができるでイメージの節約に繋がる。
用語解説
プル
リポジトリからイメージをダウンロードすることをプル(pull)という
プッシュ
リポジトリにイメージをアップロードすることをプッシュ(push)という
ローカル
相対的に見て、手元のPCやサーバーのことをローカルという 例えば、PC上にダウンロードしたイメージを指してローカルにあるイメージという。 この場合、相対的にみてダウンロード元のインターネット上のリポジトリのことをリモートレポジトリと呼ぶこともある。 このように手元の環境をローカル、ローカルから見て相手側をリモートと呼ぶ
エイリアス
別名のことをエイリアスと呼ぶ
ローカル上のDockerイメージの管理
イメージの一覧を表示するサブコマンド
docker images
イメージにタグ付けするコマンド
docker tag 元となるイメージ名 新しいイメージ名
イメージの詳細情報を表示するコマンド
docker inspec 対象のイメージ名orイメージID
ローカルのイメージを削除するコマンド
docker rmi 対象のイメージor対象のイメージID #強制したい場合は、-fコマンドを付ける docker rmi -f 対象のイメージor対象のイメージID
イメージを取得(PULL)するコマンド
docker pull 取得したいイメージ名
ビルドコンテキスト
Dockerイメージをビルドする際にDockerデーモンに送信するホストOS側のディレクトリのことをビルドコンテキストと呼ぶ。 ホストOS側に置いてあるファイルをDockerイメージに内包する場合は、ビルドコンテキスト上にファイルが存在する必要がある ビルドコンテキスト上のファイルはビルト時に全てDockerデーモンに送信されるため、ビルドに不要なファイルは含めないことが推奨されている。 あくまで一時的にDockerデーモンに送信されるだけで、どのファイルをイメージに含めるかどうかはDockerfileに定義する
Dockerfile
Dockerイメージを作成するための指示書となる設定ファイル。 DockerではデフォルトでDockerfileという名前のファイルがイメージのビルドに使用される。 Dockerでビルドを行なった場合、Dockerfileに定義された内容を上から順に処理していき、最終的な状態の環境がDockerイメージとして保存される
※ビルドとはプログラミング言語を元に実行可能ファイルや配布パッケージを処理や操作すること
ビルドプッシュ
Dockerイメージをビルドした際に、イメージのレイヤーごとにビルド結果がキャッシュされる。 Dockerfileを元にビルド内容に差がない場合、2回目以降のビルドした場合はこのビルドキャッシュが使用されるため、初回より早くビルトが完了する。 Dockerfileに変更があったり、関連するファイルに差があった場合は、ビルドキャッシュが使用されずに再度ビルドが行われる。
Dockerfileを使用したイメージビルド方法
Dockerfileからイメージをビルドするコマンド - ビルドコンテキスト配下のDockerデーモンに送られるので不要なファイルは削除するべき
docker build タグ名の指定 ビルドコンテキスト
ビルドを再度する際にはキャッシュが使われる。キャッシュを使用しない場合は-no-cacheオプションを使用する。
nginxコンテナの実行とデタッチモード
-p 8080:80でポートマッピングした場合の簡略化したネットワーク図 仮想マシンの8080ポートに来た場合、コンテナの80ポートにアクセスするようにする
バインドマウントの解説
ITの分野では、コンピュータ本体に接続した周辺機器をオペレーティングシステム(OS)などのソフトウェアに認識させ、操作・利用可能な状態にすることをマウントということがある。 ホストOS上にあるファイルをコンテナで使用できる状態にすること
DockerfileのCOPY命令、ADD命令
docker cpコマンドの説明
ホストマシンのファイルをコンテナ内にコピーする場合
$ docker cp ホスト上にコピーしたいファイルのパス \ コンテナ名orID : コピー先のパス
コンテナ内のファイルをホストマシンにコピーする場合
$ docker cp コンテナ名orID : コンテナ上のコピーしたいファイルのパス \ コピー先のパス
用語解説
標準入力
標準入力とはコンピュータ上で実行されているプログラムが特に何も指定されていない場合に標準的に利用するデータ入力元のことを指す
TTY
TTYとはteletypewriterを略したものでコンピュータの利用者が入力した文字を別の機器に送信したり、別の機器から受信した文字情報を利用者に提示したりする機能を持った端末やソフトウェアのこと
フォアグラウンド
プログラムを実行した際に処理状況や、処理結果が逐一画面に表示されるような動作をするものをフォアグラウンドと呼ぶ。 逆にバックグラウンととは処理の呼び出し後に裏側で実行され、表立って処理状況や処理結果が画面に表示されないものを言う
コンテナのライフサイクル
↓のブログの図を見るとわかりやすい
用語解説
デーモン
Linuxにおいて常駐型のプログラムのことをデーモンという。 例えば、Webサーバーのプログラムなどはデーモンとして起動し続け、クライアントからのリクエストがあった際に常に応答を返せるように常駐
コンテナのシェルに接続するコマンド
docker attachを使用する場合 ※ただし、シェルに接続できるのはコンテナシェルで実行している場合のみ。
$ docker attach コンテナ名orコンテナID
docker execを使用する場合
$ docker exec -it コンテナ名orコンテナID /bin/bash
Dockerコミットの解説
コンテナからイメージを作成するコマンド。通常は docker commitコマンド
$ docker commit コンテナ名orコンテナID イメージ名:タグ名
用語解説
リバースプロキシ
クライアントとサーバの通信の間に入って、サーバの応答を代理しつつ中継する機能、あるいはその役割を担うサーバのことをリバースプロキシという
環境変数
OSが設定値などを永久的に保存し、利用者や実行されるプログラムから設定・参照できるようにしたもの。 Dockerではコンテナ起動時に環境変数を設定することでコンテナ起動時に外からアプリケーションで使用するパラメーターやパスワードといった秘匿情報を渡すことができる
名前解決
IPネットワークにおいて、ドメイン名やコンピュータのホスト名、コンテナ名などからコンピュータが通信時に使用するIPアドレスを検索することを指す。 IPアドレスがわからないと異なるホスト間やコンテナ間で通信できないため、名前からIPアドレスを照会するためのシステムとしてDNSが使用される。 また、DNSを使わずに名前解決する方法として、hostsと呼ばれる設定ファイルにホスト名とIPアドレスの対応を記載することで、hostsファイルを元に名前解決することもできる
hostsファイル
手動でホスト名とIPアドレスの対応を管理するための設定ファイル。名前解決のために使用される。
Automated Build(自動ビルド)とは
GithubやBitbucketといったソースコードのホスティングサービスでビルドコンテキスト(Dockerfileやその他のビルドに必要なファイル群)を管理し、リポジトリ上のビルトコンテキストの内容が変更された場合に自動的にビルドを実行する仕組みのこと ここではgithubでDockerfileが変更した場合、docker hubのイメージが変更される
Docker Machineとは
Docker Machine は仮想マシン上に Docker Engine をインストールするツール。 Docker Engineを搭載した仮想マシンの作成、起動、停止、再起動などをコマンドラインから実行できるツール。 ローカルPCだけでなく、リモートのクラウドプロパイダでDockerホストを立ち上げ管理することも可能。
用語解説
ブリッジネットワーク
同一のDockerホスト上でコンテナ間通信するために使用されるネットワーク 同一のブリッジネットワークに属するコンテナ同士は相互に通信することができる
デフォルトゲートウェイ
異なるネットワークに出る場合の出口となるIPアドレスのことをデフォルトゲートウェイと呼ぶ 例えばインターネット上のサーバーのIPアドレスと通信する場合、PCはデフォルトゲートウェイを経由してインターネットに出て対象のサーバーと通信する。 この際デフォルトゲートウェイのIPを持つネットワーク機器は異なるネットワークと通信するためのルーティング情報(経路情報)が設定されている必要がある
用語解説
ループバックアドレス
ホストが自分自身のホストを指す特殊なアドレスのこと。 127.0.0.1のアドレスがループバックアドレスを指す。 また通常localhostというホスト名は127.0.0.1を指す
オーバーレイネットワーク
複数のDockerマシン(Dockerデーモンが動作するホスト)間で相互通信を可能にするためのネットワークをオーバーレイネットワークという。 ネットワーク上に存在するホストの情報や状態管理を行うためにキーバリューストア(データベース)が別途必要になる。
Dockerのデータ管理
volumeを使用したデータ管理 ボリュームとは、Docker コンテナーにおいて生成され利用されるデータを、永続的に保持する目的で利用される仕組み コンテナにマウントして使用する。複数のコンテナにマウントできる。
Docker Composeの概要
Compose とは、複数のコンテナを定義し実行する Docker アプリケーションのためのツール
Compose実行のステップ
- Dockerfileを用意するか、使用するイメージをDocker Hubに用意する
- docker-compose.ymlを定義する
- docker-compose upを実行する
用語解説(ECS)
クラスタ
ECSインスタンスを管理 複数サービスを管理
ECSインスタンス
ECSエージェントが稼働するEC2インスタンス
Effective Rubyのまとめ
業務でRubyを使用しているのですが、なんとなくで理解している部分が多いと気づいたのでRubyへの理解を深くしたいと思い、Effective Rubyを読みました!
第1章Rubyに身体をならす!
項目1 Rubyは何を真と考えているかを正確に理解しよう
- Rubyではfalseとnilを除く全ての値が真
- 多く言語と異なり、Rubyでは数値ゼロは真
- falseとnilは区別しなければいけない時はnil?メソッドを使うか、falseを左被演算子とする"=="演算子を使う
irb> class Bad
def == (other)
true
end
irb> false == Bad.new
---> false
irb> Bad.new == false
---> true
オブジェクトを扱う時にはnilかもしれないということを忘れないようにしよう
Rubyの暗号めいたPerl風機能は避けよう
定数がミュータブルなこと事に注意
- 定数を定義したと
.freezeをしてあげないと値を代入した時に定数が変更されてしまう - 配列と、配列の中身まで
freezeしたい時は↓のようにする
module Animals
Insects = [
"kabutomusi",
"kuwagata",
"gokiburi"
].map!(&:freeze).freeze
end
- 定数モジュールを作り、その中に定数を定義する。その後、モジュール自体をfreezeすればまとめて定数化できる!
実行時の警告に注意しよう
第2章クラス、オブジェクト、モジュール
Rubyが継承階層をどのように組み立てるかを頭に入れよう
- オブジェクトは変数の入れ物。各オブジェクトは特定のある1つのクラスとオブジェクトを結びつける特殊な内部変数を持っている
- クラスは、メソッドと定数の入れ物。
- スーパークラスはクラス階層内の親クラスのこと
- モジュールはある1点を除いてはクラスと全く同じ。Ruby内部ではモジュールとクラスは同じデータ構造を使って実装されているが、クラスメソッドによってそのデータ構造をどのように操作できるか制限されている(newメソッドがない)
- 特異クラスは継承階層に含まれている名前のない不可視のクラスを指すわかりにくい用語。クラスメソッドやモジュールから取り込んだメソッドを格納する場所を提供する。
- レシーバはメソッドが呼び出されるオブジェクトのこと
customer.name ↑レシーバ
- Rubyはクラス階層をサーチするだけでメソッドを見つけられる。探しているメソッドは見つからない時には、method_missingを探して再びサーチを開始する
- モジュールをインクルードすると、暗黙のうちに特異クラスが作られ、その特異クラスはクラス階層のインクルードしたクラスの上に挿入される
- 特異メソッドは同じようにクラス階層に挿入される特異クラスに格納される
superの振る舞いが一通りではないことに注意
- superは継承先のメソッドを上書きする時に、継承先のメソッドを呼びたい時に使うメソッド
class SuperSilliness < SillyBase
def m1(x, y)
super(1, 2) # 1と2を渡して呼び出し
super(x, y) # xとyを渡して呼び出し
super x, y # 上と同じ
super # 上と同じ
super # 引数なしで呼び出し
end
end
サブクラスを初期化するときにはsuperを呼び出そう
- Rubyはサブクラスのオブジェクトを作る時にはスーパークラスのinitializeメソッドを自動的に呼び出したりしない。
- 明示的に継承を使うクラスでinitializeメソッドを書く時にはsuperを使って親クラスを初期化する必要がある
Rubyの最悪の紛らわしい構文に注意しよう
構造化データの表現にはHashではなくStructを使おう
- 新しいクラスを作るほどでもない構造化データを扱うときにはHashではなくStructを使おう
- Struct::newの戻り値を定数に代入し、その定数をクラスのように扱おう
モジュールにコードをネストして名前空間を作ろう
protectedメソッドを使ってプライベートな状態を共有しよう
- privateメソッドはレシーバーに対して呼び出せない。つまり関数の形だけでしか呼び出せない
- ちなみに継承先のprivateメソッド、protectedメソッドも呼び出せる
- protectedメソッドはクラス内のインスタンスに対して呼び出せる
- レシーバを明示してprotectedメソッドを呼び出せるのは、同じクラスのオブジェクトか共通のスーパークラスからprotectedメソッドを継承しているオブジェクトだけ
クラス変数よりもクラスインスタンス変数を使うようにしよう
- クラス変数はそのクラス、サブクラス全てに共有される。つまり、サブクラスが2つあるとして同じクラス変数を2つ持っている場合共有している状態になり、どちらかのクラス変数に変更があった場合、もう一方のクラス変数も影響を受ける事になる
- 基本的にはクラス変数よりもクラスインスタンス変数を使うべき
第3章 コレクション
コレクションを書き換える前に引数として渡すコレクションのコピーを作っておこう
- Rubyのコレクションクラス(ArrayやHash)は一覧のオブジェクトを格納しているが、実際の値ではなく参照という形でやり取りされる
- オブジェクトがメソッドに引数として渡される時にも同じことが当てはまる。メソッドはオブジェクトの新しいコピーではなく、オブジェクトの参照を受け取る
- オブジェクトに変更を加えるとそのオブジェクトの参照を持っているすべてのコードから変更結果が見える。つまり、配列の要素を書き換えると配列とは別の変数で参照しているかもしれないオリジナルのオブジェクトにも影響が及ぶ
- 初期化時にコレクションを書き換える必要はないが、コレクションをいじりたい時はコレクションのコピーを使用する
- rubyのコピーするメソッドはdup, cloneの2つがあるが、dupを使用した方がいじるためには良い
- cloneはフリーズ状態や特異メソッドを引き継ぐ
- dupはフリーズ状態や特異メソッドを引き継がない
- clone, dupは作成するコピーはシャローコピーであり、要素はコピーできない。つまりコピーの要素を変更するとコピー元にも影響が出る
- オブジェクトをコピーしたいときはMarshalを使えば必要な時にディープコピーを作れる
nil、スカラーオブジェクトを配列に変換するにはArrayメソッドを使おう
- 下のクラスはtoppingsに配列を期待しているため、toppingに変え全ての引数を1つの配列にまとめてしまって可変長引数リストにしてしまいたくなるかもしれない。これにはinitializeに渡す時に""を使って展開しない限り、直接渡せなくなる
class Pizza
def initialize(toppings)
toppings.each do |topping|
add_and_price_topping(topping)
end
end
・・・
end
- Arrayメソッドを使って配列化していることを明確にしたほうが良い
- to_ary, to_aに応答する場合にはそのメソッドが呼び出される。どちらのメソッドも呼び出さない場合は、Arrayは新しい配列で包む
- ArrayメソッドにHashを渡してはならない。Hashは一連のネストされた配列に変換されてしまう
要素が含まれているかどうかの処理を効率よく行うために集合を使うことを検討しよう
- 要素が含まれているかの高速チェックはSetを使うことを検討しよう
- Setを挿入されるオブジェクトはハッシュキーとしても使えなければならない
- Setを使う前に、require('set')を実行しよう
reduceを使ってコレクションをたたみ込む方法を身につけよう
- reduceメソッドを使用することでより簡潔に書けるようになる
users.select { |u| u.age >= 21 }.map(&:name)
users.reduce([]) do |names, user|
names << user.name if user.age >= 21
names
end
- アキュムレータの初期値は必ず使おう
- reduceのブロックは必ずアキュムレータを返すようにする。現在のアキュムレータを書き換えるのは間違いないが、それをブロックから返すのを忘れないようにする ※アキュムレータとは結果が入れられるコレクション 上の例ではnames
ハッシュのデフォルト値を利用することを検討しよう
- Hashのデフォルト値を使うことを検討しよう
- ハッシュがキーを含んでいるかどうかをチェックする時には、has_key?またはその別名を使おう。つまり、存在しないキーにアクセスしたらnilを返されることを前提としてコードを書いてはならない
- 無効なキーを渡すとnilを返すことを前提としているコードにハッシュを渡さなければならない時にはデフォルト値を使ってはならない
- デフォルト値を使うよりもHash#fetchを使った方が安全な場合がある
コレクションクラスからの継承よりも委譲を使うようにしよう
- コレクションクラスからの継承よりも委譲を使うようにしよう
- 委譲のターゲットのコピーを作るinitialize_copyメソッドを忘れずに書こう
- 委譲ターゲットに対応するメッセージを送ってからsuperを呼び出すという形でfreeze, taint, untaintメソッドを書こう
第4章 例外
raiseにはただの文字列ではなくカスタム例外を渡そう
- Rubyではエラーを生じさせるときはエラーの詳細がわかるようにクラスを指定してあげるべき
- 新しい例外クラスは簡単に以下の3つの規則に従うだけで簡単に作成できる
- 新しい例外クラスは標準例外クラスのどれかを継承しなければならない。ほかのものをraiseに渡そうとするとTypeErrorが起きる
- 標準例外クラスはExceptionをルートとする回想構造を形成している。しかし、Exceptionとそのサブクラスのいくつかは一般にプログラムをクラッシュさせる低水準エラーと考えられる。標準例外クラスの大多数はStandErrorを継承している
- 技術的に必要とされているわけではないが、例外クラス名は、Errorで終わるようにするのが一般的なやり方
- 例外としてraiseに文字列を渡すのは避けよう。この場合汎用のRuntimeErrorオブジェクトが使われる。そうではなく、カスタム例外クラスを作ろう
- カスタム例外クラスはStandErrorを継承し、クラス名がErrorで終わるようにしよう
- 1つのプロジェクトのために複数の例外クラスを作る時には、まずStandErrorを継承する基底クラスを作り、他の例外クラスはそのカスタム基底クラスを継承するように構成しよう
- initializeでエラーメッセージを設定する時には、raiseでエラーメッセージを設定するとinitializeのメッセージが上書きされてしまうことに注意
できる限り最も対象の狭い例外を処理するようにしよう
- 修復方法がわかっている特定の例外だけをrescueで捕まえよう
- 例外を捕まえる時には、最も限定されたタイプのものを最初に処理しよう。例外の階層構造の上位にあるものほど、rescue節は下流に作る
- StandErrorのような汎用例外クラスをrescue節で捕まえるのは避けよう
- rescue節で例外を生成すると、新しい例外が現在の例外を押し退け、現在のスコープを抜けて例外処理を最初からやり直す
リソースはブロックとensureで管理しよう
- 確保したリソースを開放するためにはensure節を書こう -リソース管理を抽象化するために、クラスメソッドでblockとensureパターンを使おう
- ensure節で変数を使う時には、その前に変数が初期化されているかどうかを確かめよう
ensure節は最後まで実行して抜けるように作ろう
- ensure節のなかでreturn文を明示的に使うのは避けなければならない
- ensureの中でthrowを使ってはならない
- 反復処理では、ensure節の中でnextやbreakを使ってはならない。たいていの場合は逆にbeginの中に反復処理を配置する方が正しいものだ
- より一般的にensure節の中で制御フローを変更してはならない。制御フローの変更はrescue節で行うべき
スコープから飛び出したい時にはraiseではなくthrowを使おう
- 複雑な制御フローが必要な時には、raiseではなく、throwを使うようにする。throwを使うと、ボーナスとしてスタックの上位にオブジェクトを送ることができる。catchの戻り値はそのオブジェクトになる。
- できる限り単純な制御構造を使う。 catchとthrowの組み合わせは単純にreturnでスコープから抜け出すメソッドとそれに対する呼び出しで置き換えられることが多い。
メタプログラミング
メタプログラミングとはクラス、モジュール、個々のオブジェクトの振る舞いを変更すること。「メタプログラミング」はRubyの最も強力な機能の1つであり、最も危険な機能
モジュール、クラスフックを使いこなそう
- 全てのフックメソッドは特異メソッドとして定義しなければならない
- メソッドが追加、削除、定義解除されるときに呼び出されるフックはメソッド名しか受け取らず、変更が行われるクラスは与えられない。クラス名が知りたい場合にはselfの値を使う
- singleton_method_addedを定義すると、自分自身の呼び出しが発生する
- extend_object, append_features, prepend_featuresメソッドをオーバーライドしてはならない。代わりに、extended, inclued, prependedフックを使おう
クラスフックからはsuperを呼び出そう
- クラスフックの中にはsuper呼び出しを入れよう
- superを呼ばないとinheritaedを制御できない(他のモジュールでinheritedが使われていたら)
method_missingではなくdefine_methodを使うようにしよう
- method_missingではなくdefine_methodを使うようにしよう
- どうしてもmethod_missingを使わなければならない時には、respond_to_missing?を定義することを検討しよう
evalの多様な変種間の違いを把握しよう
- instance_evalやinstance_execで定義されるメソッドは特異メソッドである
- class_eval, module_eval, class_exec, module_execメソッドのレシーバはモジュール、クラスに限られる。これらのどれかで定義されたメソッドはインスタンスメソッドになる
モンキーパッチは代わりとなるものを検討しよう
モンキーパッチとは言語の組み込みクラスやライブラリ、その他外部ライブラリの挙動を、動的に拡張する仕組み 参考資料
- Refinementsはもう実験的機能ではなくなったが、機能の成熟とともに変化する可能性はまだ残っている
- Refinementsはそれを使いたい個々のレキシカルスコープでアクティブ化しなければならない
参考資料
https://www.amazon.co.jp/Effective-Ruby-Peter-J-Jones/dp/4798139823